

[출처] https://docs.streamlit.io/develop/concepts/architecture
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
1. Run your Streamlit app
Streamlit으로 작업하는 방법은 간단합니다. 먼저 일반 Python 스크립트에 몇 가지 Streamlit 명령을 뿌린 다음 실행하면 됩니다. 사용 사례에 따라 스크립트를 실행하는 몇 가지 방법을 나열합니다.
1.1. Use stremlit run
스크립트(예: your_script.py)를 만든 후 가장 쉽게 실행할 수 있는 방법은 streamlit run을 사용하는 것입니다:
streamlit run your_script.py위와 같이 스크립트를 실행하면 로컬 스트림릿 서버가 가동되고 앱이 기본 웹 브라우저의 새 탭에서 열립니다.
1.2. Pass arguments to your script
스크립트에 일부 사용자 정의 인수를 전달할 때는 두 개의 대시 뒤에 인수를 전달해야 합니다. 그렇지 않으면 인수가 Streamlit 자체에 대한 인수로 해석됩니다:
streamlit run your_script.py [-- script args]1.3. Pass a URL to streamlit run
streamlit run에 URL을 전달할 수도 있습니다! 이 기능은 GitHub Gist와 같이 스크립트가 원격으로 호스팅되는 경우에 유용합니다. 예를 들어
streamlit run https://raw.githubusercontent.com/streamlit/demo-uber-nyc-pickups/master/streamlit_app.py1.4. Run Streamlit as a Python module
Streamlit을 실행하는 또 다른 방법은 Python 모듈로 실행하는 것입니다. 이 방법은 Streamlit과 함께 작동하도록 PyCharm과 같은 IDE를 구성할 때 유용합니다:
# Running
python -m streamlit run your_script.py# is equivalent to:
streamlit run your_script.py2. Understanding Streamlit's client-server architecture
streamlit 앱은 클라이언트-서버 구조를 가지고 있습니다. 앱의 Python 백엔드가 서버입니다. 브라우저를 통해 보는 프론트엔드는 클라이언트입니다. 로컬에서 앱을 개발하는 경우 컴퓨터에서 서버와 클라이언트를 모두 실행합니다. 누군가 로컬 또는 글로벌 네트워크에서 앱을 보는 경우 서버와 클라이언트는 서로 다른 컴퓨터에서 실행됩니다. 앱을 공유하거나 배포하려는 경우 일반적인 함정을 피하려면 이 클라이언트-서버 구조를 이해하는 것이 중요합니다.
2.1. Python backend (server)
streamlit run your_app.py 명령을 실행하면 컴퓨터에서 Python을 사용하여 Streamlit 서버를 시작합니다. 이 서버는 앱의 두뇌 역할을 하며 앱을 보는 모든 사용자에 대한 연산을 수행합니다. 사용자가 로컬 네트워크에서 앱을 보든 인터넷을 통해 앱을 보든, Streamlit 서버는 streamlit 실행으로 앱이 초기화된 컴퓨터에서 실행됩니다. streamlit 서버를 실행하는 머신을 호스트라고도 합니다.
2.2. Browser frontend (client)
누군가 브라우저를 통해 앱을 보는 경우, 해당 디바이스는 streamlit 클라이언트입니다. 앱을 실행하거나 개발 중인 동일한 컴퓨터에서 앱을 보는 경우 서버와 클라이언트는 공교롭게도 동일한 컴퓨터에서 실행됩니다. 그러나 사용자가 로컬 네트워크나 인터넷을 통해 앱을 보는 경우 클라이언트는 서버와 다른 컴퓨터에서 실행됩니다.
2.3. Server-client impact on app design
스트림릿 앱을 구축할 때 다음 고려 사항을 염두에 두세요:
- 스트림릿 앱을 실행하거나 호스팅하는 컴퓨터는 모든 사용자에게 앱을 실행하는 데 필요한 컴퓨팅 및 저장 공간을 제공해야 하며 동시 사용자를 처리할 수 있는 적절한 크기여야 합니다.
- 앱은 사용자의 파일, 디렉터리 또는 OS에 액세스할 수 없습니다. 앱은 사용자가 st.file_uploader와 같은 위젯을 통해 앱에 업로드한 특정 파일만 사용할 수 있습니다.
- 앱이 카메라 등 주변 장치와 통신하는 경우, 사용자의 브라우저를 통해 해당 장치에 액세스하고 클라이언트(프론트엔드)와 서버(백엔드) 간에 올바르게 통신하는 Streamlit 명령 또는 사용자 정의 구성 요소를 사용해야 합니다.
- 앱이 Python 외부의 프로그램이나 프로세스를 열거나 사용하는 경우 서버에서 실행될 수 있습니다. 예를 들어 웹브라우저를 사용하여 사용자에게 브라우저를 열어주고 싶지만 네트워크를 통해 앱을 볼 때 예상대로 작동하지 않고 사용자가 볼 수 없는 Streamlit 서버에서 브라우저가 열리게 됩니다.
3. The app chrome
스트림릿 앱 오른쪽 상단에는 개발하는 데 도움이 되는 몇 가지 위젯이 있습니다. 이러한 위젯은 시청자가 앱을 사용할 때에도 도움이 됩니다. 이를 '앱 크롬'이라고 부릅니다. 크롬에는 상태 영역, 도구 모음 및 앱 메뉴가 포함됩니다.
앱 메뉴는 구성할 수 있습니다. 기본적으로 관리자 액세스 권한이 있는 계정에 로그인한 상태에서 로컬 또는 스트림릿 커뮤니티 클라우드에서 앱을 볼 때 앱 메뉴에서 개발자 옵션에 액세스할 수 있습니다. 앱을 보는 동안 오른쪽 상단에 있는 아이콘을 클릭하면 메뉴에 액세스할 수 있습니다.
3.1. Menu options
메뉴는 두 섹션으로 나뉩니다. 위쪽 섹션에는 모든 시청자가 사용할 수 있는 옵션이 있고 아래쪽 섹션에는 개발자를 위한 옵션이 있습니다. 이 페이지 끝에서 이 메뉴를 커스터마이징하는 방법에 대해 자세히 알아보세요.
3.2. Rerun
앱 메뉴에서 '다시 실행'을 클릭하여 앱의 재실행을 수동으로 트리거할 수 있습니다. 이 재실행은 세션을 재설정하지 않습니다. st.session_state에 저장된 위젯 상태와 값은 그대로 유지됩니다. 바로 가기로 앱 메뉴를 열지 않고 키보드의 "R"을 눌러 앱을 다시 실행할 수 있습니다(현재 입력 요소에 집중하고 있지 않은 경우).
3.3. Settings
'Settings' 옵션을 사용하면 앱이 실행되는 동안 앱의 모양을 제어할 수 있습니다. 앱을 로컬에서 보는 경우 소스 코드의 변경 사항에 앱이 응답하는 방식을 설정할 수 있습니다. 개발 흐름에 대한 자세한 내용은 기본 개념에서 확인하세요. 스크립트 내에서 설정하지 않더라도 st.set_page_config를 사용하여 앱이 와이드 모드로 표시되도록 강제할 수도 있습니다.
Theme settings
앱 메뉴에서 'Settings'을 클릭한 후 앱의 기본 테마로 'Light', 'Dark' 또는 'Use system setting' 중에서 선택할 수 있습니다. 테마를 색상별로 수정하려면 "Edit active theme"을 클릭합니다.
'인쇄'를 클릭하거나 키보드 단축키(⌘+P 또는 Ctrl+P)를 사용하여 인쇄 대화 상자를 엽니다. 이 옵션은 브라우저에 내장된 PDF로 인쇄 기능을 사용합니다. 인쇄물의 모양을 수정하려면 다음을 수행하면 됩니다:
- 인쇄하기 전에 사이드바를 펼치거나 접어서 인쇄에 포함하거나 제외합니다.
- 앱에서 사이드바의 오른쪽 테두리를 클릭하고 끌어서 원하는 너비로 크기를 조정합니다.
- 어두운 모드로 인쇄하는 경우 인쇄 대화 상자에서 '배경 그래픽'을 활성화해야 할 수 있습니다.
- 페이지에서 요소가 잘리지 않도록 설정에서 와이드 모드를 비활성화하거나 인쇄 배율을 조정해야 할 수도 있습니다.
Record a screencast
앱에서 바로 화면 녹화를 간편하게 할 수 있습니다! 화면 녹화 기능은 최신 버전의 Chrome, Edge, Firefox에서 지원됩니다. 호환성을 위해 사용 중인 브라우저가 최신 버전인지 확인하세요. 현재 설정에 따라 브라우저에 화면을 녹화하거나 음성 해설을 녹음하는 경우 마이크를 사용할 수 있는 권한을 부여해야 할 수도 있습니다.
- 앱을 보는 동안 오른쪽 상단에서 앱 메뉴를 엽니다.
- "Record a screencast" 를 클릭합니다.
- 마이크를 통해 오디오를 녹음하려면 " Also record audio"를 선택하고
- " Start recording"를 클릭합니다. (브라우저에서 화면 녹화 또는 마이크 사용을 허용하라는 메시지가 표시될 수 있습니다.)
- 나열된 옵션 중에서 녹화할 탭, 창 또는 모니터를 선택합니다. 인터페이스는 브라우저에 따라 달라집니다.
- "Share"를 클릭합니다.
- 녹화하는 동안 앱의 탭과 앱 메뉴 아이콘에 빨간색 원이 표시됩니다. 녹화를 취소하려면 앱 하단의 ' Stop sharing '를 클릭합니다.
- 녹음이 끝나면 키보드의 'Esc'를 누르거나 앱 메뉴에서 ' Stop recording '를 클릭합니다.
- 브라우저의 안내에 따라 녹화를 저장합니다. 저장된 녹화물은 브라우저의 다운로드 저장 위치에서 사용할 수 있습니다.
3.4. About
' About' 옵션에서 실행 중인 스트림릿의 버전을 편리하게 확인할 수 있습니다. 또한 개발자는 st.set_page_config를 사용하여 여기에 표시되는 메시지를 사용자 지정할 수 있습니다.
3.5. Developer options
기본적으로 개발자 옵션은 앱을 로컬에서 볼 때 또는 관리자 권한으로 로그인한 상태에서 커뮤니티 클라우드 앱을 볼 때만 표시됩니다. 모든 사용자가 이러한 옵션을 사용할 수 있도록 하려면 메뉴를 사용자 지정할 수 있습니다.
3.6. Clear cache
앱 메뉴에서 '캐시 지우기'를 클릭하거나 입력 요소에 집중하지 않은 상태에서 키보드의 'C'를 눌러 앱의 캐시를 재설정합니다. 이렇게 하면 @st.cache_data 및 @st.cache_resource에 대해 캐시된 모든 항목이 제거됩니다.
3.7. Deploy this app
Git 리포지토리 내에서 로컬로 앱을 실행하는 경우 몇 번의 클릭만으로 앱을 Streamlit 커뮤니티 클라우드에 배포할 수 있습니다! 시작하기 전에 작업이 온라인 GitHub 리포지토리에 푸시되었는지 확인하세요. 최대한의 편의를 위해 이미 커뮤니티 클라우드 계정을 만들고 로그인했는지 확인하세요.
1. 앱 메뉴 아이콘 옆의 'Deploy'를 클릭합니다.
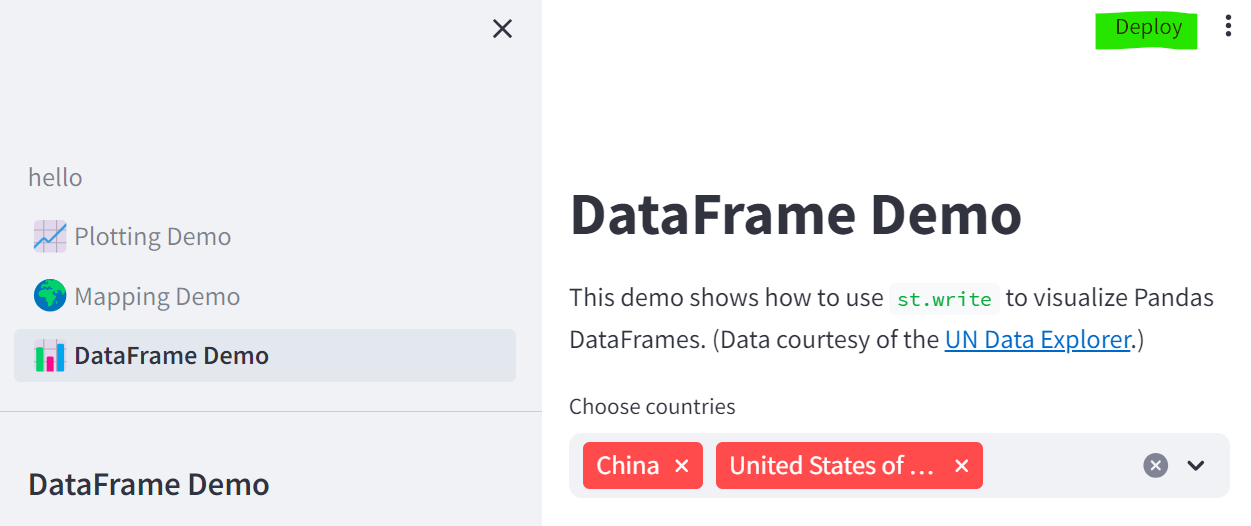
2. "Deploy now"를 클릭

3. 커뮤니티 클라우드의 "앱 배포" 페이지로 이동합니다. 앱의 리포지토리, 브랜치 및 파일 이름이 현재 앱과 일치하도록 미리 채워집니다! 스트림릿 커뮤니티 클라우드에 앱을 배포하는 방법에 대해 자세히 알아보세요.
3.8. Customize the menu
앱 구성에서 client.toolbarMode를 사용하면 다음과 같은 방법으로 앱 메뉴를 표시할 수 있습니다:
- "developer" — 모든 시청자에게 개발자 옵션을 표시합니다.
- "viewer" — 모든 시청자에게 개발자 옵션을 숨깁니다.
- "minimal" — 외부에서 설정한 옵션만 표시합니다. 이러한 옵션은 st.set_page_config를 통해 선언하거나 스트림릿 커뮤니티 클라우드를 통해 채울 수 있습니다.
- "auto" — 이 옵션이 기본값이며, 앱의 관리자 계정으로 로그인하여 로컬호스트를 통해 액세스하거나 스트림릿 커뮤니티 클라우드를 통해 액세스할 때 개발자 옵션이 표시됩니다. 그렇지 않으면 개발자 옵션이 표시되지 않습니다.
4. Caching overview
Streamlit은 모든 사용자 상호작용이나 코드 변경 시 스크립트를 위에서 아래로 실행합니다. 이 실행 모델은 개발을 매우 쉽게 만듭니다. 하지만 여기에는 두 가지 주요 과제가 있습니다:
- 오래 실행되는 함수는 반복해서 실행되므로 앱 속도가 느려집니다.
- 개체가 반복해서 다시 생성되므로 재실행 또는 세션에서 지속하기 어렵습니다.
하지만 걱정하지 마세요! 스트림릿은 내장된 캐싱 메커니즘으로 두 가지 문제를 모두 해결할 수 있습니다. 캐싱은 느린 함수 호출의 결과를 저장하므로 한 번만 실행하면 됩니다. 이렇게 하면 앱 속도가 훨씬 빨라지고 재실행 시에도 객체를 유지하는 데 도움이 됩니다. 캐시된 값은 앱의 모든 사용자가 사용할 수 있습니다. 세션 내에서만 액세스할 수 있는 결과를 저장해야 하는 경우 세션 상태를 대신 사용하세요.
4.1. Minimal example
Streamlit에서 함수를 캐시하려면 두 가지 데코레이터(st.cache_data 또는 st.cache_resource) 중 하나를 사용하여 함수를 데코레이션해야 합니다:
@st.cache_data
def long_running_function(param1, param2):
return …이 예제에서 @st.cache_data로 long_running_function을 꾸미면 함수가 호출될 때마다 Streamlit이 두 가지를 확인합니다:
- 입력 매개변수의 값(이 경우 param1 및 param2).
- 함수 내부의 코드입니다.
스트림릿이 이러한 매개변수 값과 함수 코드를 처음 본 경우, 함수를 실행하고 반환값을 캐시에 저장합니다. 다음에 동일한 매개변수와 코드로 함수가 호출될 때(예: 사용자가 앱과 상호 작용할 때) Streamlit은 함수 실행을 건너뛰고 대신 캐시된 값을 반환합니다. 개발 중에 함수 코드가 변경되면 캐시가 자동으로 업데이트되어 최신 변경 사항이 캐시에 반영됩니다.
앞서 언급했듯이 캐싱 데코레이터에는 두 가지가 있습니다:
- st.cache_data는 데이터를 반환하는 계산을 캐시하는 데 권장되는 방법으로, CSV에서 데이터 프레임 로드, NumPy 배열 변환, API 쿼리 또는 직렬화 가능한 데이터 객체(str, int, float, DataFrame, array, list, ...)를 반환하는 기타 함수 등을 캐시합니다. 각 함수 호출 시 데이터의 새 복사본을 생성하여 돌연변이와 경쟁 조건으로부터 안전합니다. 대부분의 경우 st.cache_data의 동작이 원하는 것이므로 확실하지 않은 경우 st.cache_data로 시작하여 작동하는지 확인하세요!
- st.cache_resource는 여러 번 로드하지 않으려는 직렬화 불가능한 객체인 ML 모델이나 데이터베이스 연결과 같은 글로벌 리소스를 캐시하는 데 권장되는 방법입니다. 이를 사용하면 복사나 복제 없이 앱의 모든 재실행 및 세션에서 이러한 리소스를 공유할 수 있습니다. 캐시된 반환값을 변경하면 캐시에 있는 객체가 직접 변경된다는 점에 유의하세요(자세한 내용은 아래 참조).
4.2. Basic usage
4.2.1. st.cache_data
st.cache_data는 데이터를 반환하는 모든 함수(데이터프레임, NumPy 배열, str, int, float 또는 기타 직렬화 가능한 유형 등)에 사용할 수 있는 명령어입니다. 거의 모든 사용 사례에 적합한 명령입니다! 각 사용자 세션 내에서 @st.cache_data로 장식된 함수는 캐시된 반환 값의 복사본을 반환합니다(값이 이미 캐시된 경우).
Usage
st.cache_data 사용의 예를 살펴보겠습니다. 앱이 인터넷에서 50MB의 CSV 파일인 Uber 차량 공유 데이터 집합을 데이터 프레임으로 로드한다고 가정해 보겠습니다:
def load_data(url):
df = pd.read_csv(url) # 👈 Download the data
return df
df = load_data("https://github.com/plotly/datasets/raw/master/uber-rides-data1.csv")
st.dataframe(df)
st.button("Rerun")load_data 함수를 실행하는 데는 인터넷 연결에 따라 2~30초가 걸립니다. (팁: 연결 속도가 느린 경우 이 5MB 데이터 세트를 대신 사용하세요). 캐싱을 사용하지 않으면 앱이 로드될 때마다 또는 사용자 상호 작용이 있을 때마다 다운로드가 다시 실행됩니다. 추가한 버튼을 클릭하여 직접 사용해 보세요! 좋은 경험은 아니네요... 😕
이제 load_data에 @st.cache_data 데코레이터를 추가해 보겠습니다:
@st.cache_data # 👈 Add the caching decorator
def load_data(url):
df = pd.read_csv(url)
return df
df = load_data("https://github.com/plotly/datasets/raw/master/uber-rides-data1.csv")
st.dataframe(df)
st.button("Rerun")앱을 다시 실행합니다. 처음 실행할 때만 다운로드 속도가 느려지는 것을 확인할 수 있습니다. 이후 모든 재실행은 거의 즉각적으로 이루어집니다! 💨
Behavior
어떻게 작동할까요? st.cache_data의 동작을 단계별로 살펴보겠습니다:
- 첫 번째 실행에서 Streamlit은 지정된 매개변수 값(CSV 파일의 URL)으로 load_data 함수를 호출한 적이 없음을 인식하여 함수를 실행하고 데이터를 다운로드합니다.
- 이제 캐싱 메커니즘이 활성화됩니다. 반환된 데이터 프레임은 피클을 통해 직렬화(바이트로 변환)되고 (url 매개변수 값과 함께) 캐시에 저장됩니다.
- 다음 실행에서 Streamlit은 특정 URL이 포함된 load_data 항목이 있는지 캐시에서 확인합니다. 하나가 있습니다! 따라서 함수를 다시 실행하고 데이터를 다시 다운로드하는 대신 캐시된 객체를 검색하여 데이터프레임으로 역직렬화한 후 반환합니다.
캐시된 객체를 직렬화하고 역직렬화하는 이 프로세스는 원본 데이터프레임의 복사본을 생성합니다. 이 복사 동작은 불필요한 것처럼 보일 수 있지만, 데이터 객체를 캐시할 때 돌연변이와 동시성 문제를 효과적으로 방지할 수 있기 때문에 꼭 필요한 작업입니다. 이에 대한 자세한 내용은 아래의 '변이 및 동시성 문제' 섹션을 참조하세요.
Warning
st.cache_data는 안전하지 않은 것으로 알려진 피클 모듈을 암시적으로 사용합니다. 캐시된 함수가 반환하는 모든 데이터는 피클되어 저장되었다가 검색 시 피클이 해제됩니다. 피클 해제 중에 임의의 코드를 실행하는 악성 피클 데이터를 구성할 수 있으므로 캐시된 함수가 신뢰할 수 있는 값을 반환하는지 확인하세요. 안전하지 않은 모드에서 신뢰할 수 없는 소스에서 가져왔거나 변조되었을 수 있는 데이터는 절대로 로드하지 마세요. 신뢰할 수 있는 데이터만 로드하세요.
Examples
DataFrame transformations
위의 예제에서는 이미 데이터프레임 로드를 캐시하는 방법을 보여드렸습니다. df.filter, df.apply 또는 df.sort_values와 같은 데이터프레임 변환을 캐시하는 것도 유용할 수 있습니다. 특히 큰 데이터프레임의 경우 이러한 작업이 느려질 수 있습니다.
@st.cache_data
def transform(df):
df = df.filter(items=['one', 'three'])
df = df.apply(np.sum, axis=0)
return dfArray computations
마찬가지로 NumPy 배열에서 계산을 캐시하는 것이 합리적일 수 있습니다:
@st.cache_data
def add(arr1, arr2):
return arr1 + arr2Database queries
일반적으로 데이터베이스로 작업할 때 앱에 데이터를 로드하기 위해 SQL 쿼리를 작성합니다. 이러한 쿼리를 반복적으로 실행하면 속도가 느려지고 비용이 발생하며 데이터베이스의 성능이 저하될 수 있습니다. 앱에서 데이터베이스 쿼리를 캐싱하는 것을 적극 권장합니다. 자세한 예시는 스트림릿을 다양한 데이터베이스에 연결하는 방법에 대한 가이드를 참조하세요.
connection = database.connect()
@st.cache_data
def query():
return pd.read_sql_query("SELECT * from table", connection)
Tip
데이터베이스에서 새로운 결과를 얻으려면 ttl(유효 시간)을 설정해야 합니다. st.cache_data(ttl=3600)를 설정하면 1시간(3600초) 후에 Streamlit은 캐시된 값을 모두 무효화하고 캐시된 함수를 다시 실행합니다. 자세한 내용은 캐시 크기 및 기간 제어하기를 참조하세요.
API calls
마찬가지로 API 호출을 캐시하는 것이 좋습니다. 이렇게 하면 속도 제한도 피할 수 있습니다.
@st.cache_data
def api_call():
response = requests.get('https://jsonplaceholder.typicode.com/posts/1')
return response.json()Running ML models (inference)
복잡한 머신 러닝 모델을 실행하면 상당한 시간과 메모리를 사용할 수 있습니다. 동일한 계산을 반복해서 다시 실행하지 않으려면 캐싱을 사용하세요.
@st.cache_data
def run_model(inputs):
return model(inputs)4.2.2. st.cache_resource
st.cache_resource는 모든 사용자, 세션 및 재실행에서 전역적으로 사용할 수 있어야 하는 '리소스'를 캐시하는 데 적합한 명령입니다. 특히 데이터베이스 연결 및 ML 모델을 캐싱하는 데 st.cache_data보다 사용 사례가 더 제한적입니다. 각 사용자 세션 내에서 @st.cache_resource-decorated 함수는 반환 값의 캐시된 인스턴스를 반환합니다(값이 이미 캐시된 경우). 따라서 st.cache_resource에 의해 캐시된 객체는 싱글톤처럼 작동하며 변경될 수 있습니다.
Usage
st.cache_resource의 예로 일반적인 머신 러닝 앱을 살펴보겠습니다. 첫 번째 단계로 ML 모델을 로드해야 합니다. Hugging Face의 트랜스포머 라이브러리를 사용하여 이 작업을 수행합니다:
from transformers import pipeline
model = pipeline("sentiment-analysis") # 👈 Load the model이 코드를 스트림릿 앱에 직접 넣으면 앱이 재실행하거나 사용자가 상호 작용할 때마다 모델을 로드합니다. 모델을 반복적으로 로드하면 두 가지 문제가 발생합니다:
- 모델을 로드하는 데 시간이 걸리고 앱 속도가 느려집니다.
- 각 세션은 모델을 처음부터 로드하므로 엄청난 양의 메모리를 차지합니다.
대신 모델을 한 번 로드하고 모든 사용자와 세션에서 동일한 객체를 사용하는 것이 훨씬 더 합리적일 것입니다. 이것이 바로 st.cache_resource의 사용 사례입니다! 이를 앱에 추가하고 사용자가 입력한 텍스트를 처리해 보겠습니다:
from transformers import pipeline
@st.cache_resource # 👈 Add the caching decorator
def load_model():
return pipeline("sentiment-analysis")
model = load_model()
query = st.text_input("Your query", value="I love Streamlit! 🎈")
if query:
result = model(query)[0] # 👈 Classify the query text
st.write(result)이 앱을 실행하면 앱이 앱이 시작될 때 load_model을 한 번만 호출하는 것을 볼 수 있습니다. 이후 실행 시에는 캐시에 저장된 동일한 모델을 재사용하므로 시간과 메모리가 절약됩니다!
Behavior
st.cache_resource를 사용하는 것은 st.cache_data를 사용하는 것과 매우 유사합니다. 하지만 동작에는 몇 가지 중요한 차이점이 있습니다:
- st.cache_resource는 캐시된 반환 값의 복사본을 생성하지 않고 대신 객체 자체를 캐시에 저장합니다. 함수의 반환 값에 대한 모든 변이는 캐시에 있는 객체에 직접 영향을 미치므로 여러 세션의 변이가 문제를 일으키지 않도록 해야 합니다. 즉, 반환값은 스레드에 안전해야 합니다.
Warning
스레드에 안전하지 않은 객체에 st.cache_resource를 사용하면 충돌이나 데이터 손상이 발생할 수 있습니다. 자세한 내용은 아래 변이 및 동시성 문제에서 확인하세요.
- 복사본을 만들지 않으면 캐시된 반환 객체의 전역 인스턴스가 하나만 존재하므로 메모리를 절약할 수 있습니다(예: 대규모 ML 모델 사용 시). 컴퓨터 과학 용어로 싱글톤을 생성하는 것입니다.
- 함수의 반환값은 직렬화할 필요가 없습니다. 이 동작은 데이터베이스 연결, 파일 핸들, 스레드 등 본질적으로 직렬화할 수 없는 유형에 유용합니다. 이러한 객체는 st.cache_data로 캐싱할 수 없습니다.
Examples
Database connections
st.cache_resource는 데이터베이스에 연결할 때 유용합니다. 일반적으로 모든 쿼리에 대해 전역적으로 재사용하려는 연결 객체를 생성합니다. 실행할 때마다 새 연결 객체를 생성하는 것은 비효율적이며 연결 오류가 발생할 수 있습니다. st.cache_resource가 바로 이러한 문제를 해결할 수 있습니다(예: Postgres 데이터베이스):
@st.cache_resource
def init_connection():
host = "hh-pgsql-public.ebi.ac.uk"
database = "pfmegrnargs"
user = "reader"
password = "NWDMCE5xdipIjRrp"
return psycopg2.connect(host=host, database=database, user=user, password=password)
conn = init_connection()물론 다른 데이터베이스에도 동일한 작업을 수행할 수 있습니다. 자세한 예시는 스트림릿을 데이터베이스에 연결하는 방법에 대한 가이드를 참조하세요.
Loading ML models
앱은 항상 ML 모델을 캐시하여 새 세션마다 다시 메모리에 로드되지 않도록 해야 합니다. 위의 예시에서 🤗 Hugging Face 모델에서 어떻게 작동하는지 확인하세요. 파이토치, 텐서플로 등에서도 동일한 작업을 수행할 수 있습니다. 다음은 PyTorch의 예시입니다:
@st.cache_resource
def load_model():
model = torchvision.models.resnet50(weights=ResNet50_Weights.DEFAULT)
model.eval()
return model
model = load_model()4.2.3. Deciding which caching decorator to use
위의 섹션에서는 각 캐싱 데코레이터에 대한 일반적인 예시를 많이 소개했습니다. 하지만 어떤 캐싱 데코레이터를 사용할지 결정하기 쉽지 않은 엣지 케이스도 있습니다. 결국 모든 것은 '데이터'와 '리소스'의 차이로 귀결됩니다:
- 데이터는 직렬화 가능한 객체(pickle을 통해 바이트로 변환할 수 있는 객체)로, 디스크에 쉽게 저장할 수 있습니다. 일반적으로 데이터베이스나 파일 시스템에 저장하는 모든 유형, 즉 str, int, float 같은 기본 유형은 물론 배열, DataFrame, 이미지 또는 이러한 유형의 조합(목록, 튜플, 딕트 등)을 상상해 보세요.
- 리소스는 일반적으로 디스크나 데이터베이스에 저장하지 않는 직렬화할 수 없는 객체입니다. 리소스는 데이터베이스 연결, ML 모델, 파일 핸들, 스레드 등과 같이 더 복잡하고 비영구적인 객체인 경우가 많습니다.
위에 나열된 유형을 보면 파이썬의 대부분의 객체가 "데이터"라는 것을 알 수 있습니다. 그렇기 때문에 거의 모든 사용 사례에서 st.cache_data가 올바른 명령어입니다. st.cache_resource는 특정 상황에서만 사용해야 하는 좀 더 이색적인 명령어입니다.
또는 너무 많은 생각을 하고 싶지 않다면 아래 표에서 사용 사례 또는 반환 유형을 찾아보세요 😉:
| Use case | Typical return types | Caching decorator |
| Reading a CSV file with pd.read_csv | pandas.DataFrame | st.cache_data |
| Reading a text file | str, list of str | st.cache_data |
| Transforming pandas dataframes | pandas.DataFrame, pandas.Series | st.cache_data |
| ... |
나머지 목록은 https://docs.streamlit.io/develop/concepts/architecture/caching 참고
4.3. Advanced usage
4.3.1 Controlling cache size and duration
앱이 장시간 실행되고 지속적으로 기능을 캐시하는 경우 두 가지 문제가 발생할 수 있습니다:
- 캐시가 너무 커서 앱의 메모리가 부족합니다.
- 데이터베이스에서 오래된 데이터를 캐시했기 때문에 캐시에 있는 개체가 부실해집니다.
두 캐싱 데코레이터 모두에 사용할 수 있는 ttl 및 max_entries 매개 변수를 사용하여 이러한 문제를 해결할 수 있습니다.
The ttl (time-to-live) parameter
ttl은 캐시된 함수의 유효 기간을 설정합니다. 이 시간이 다 되어 함수를 다시 호출하면 앱은 캐시된 이전 값을 모두 삭제하고 함수가 다시 실행됩니다. 그러면 새로 계산된 값이 캐시에 저장됩니다. 이 동작은 오래된 데이터(문제 2)와 캐시가 너무 커지는 것(문제 1)을 방지하는 데 유용합니다. 특히 데이터베이스나 API에서 데이터를 가져올 때는 오래된 데이터를 사용하지 않도록 항상 ttl을 설정해야 합니다. 다음은 예시입니다:
@st.cache_data(ttl=3600) # 👈 Cache data for 1 hour (=3600 seconds)
def get_api_data():
data = api.get(...)
return data
Tip
ttl=datetime.timedelta(hours=1)와 같이 timedelta를 사용하여 ttl 값을 설정할 수도 있습니다.
The max_entries parameter
max_entries는 캐시의 최대 항목 수를 설정합니다. 캐시 항목 수의 상한은 특히 큰 개체를 캐시할 때 메모리를 제한하는 데 유용합니다(문제 1). 새 항목이 전체 캐시에 추가되면 가장 오래된 항목이 제거됩니다. 다음은 예시입니다:
@st.cache_data(max_entries=1000) # 👈 Maximum 1000 entries in the cache
def get_large_array(seed):
np.random.seed(seed)
arr = np.random.rand(100000)
return arr4.3.2. Customizing the spinner
기본적으로 스트림릿은 캐시된 함수가 실행 중일 때 앱에 작은 로딩 스피너를 표시합니다. 두 캐싱 데코레이터 모두에 사용할 수 있는 show_spinner 매개변수를 사용하여 쉽게 수정할 수 있습니다:
@st.cache_data(show_spinner=False) # 👈 Disable the spinner
def get_api_data():
data = api.get(...)
return data
@st.cache_data(show_spinner="Fetching data from API...") # 👈 Use custom text for spinner
def get_api_data():
data = api.get(...)
return data4.3.3. Excluding input parameters
캐시된 함수에서 모든 입력 매개변수는 해시 가능해야 합니다. 그 이유와 의미를 간단히 설명하겠습니다. 함수가 호출되면 Streamlit은 매개변수 값을 살펴보고 이전에 캐시된 적이 있는지 확인합니다. 따라서 여러 함수 호출에서 매개변수 값을 비교할 수 있는 신뢰할 수 있는 방법이 필요합니다. 문자열이나 정수의 경우 간단하지만 임의의 객체의 경우 복잡합니다! Streamlit은 해싱을 사용해 이를 해결합니다. 매개변수를 안정적인 키로 변환하고 해당 키를 저장합니다. 다음 함수 호출 시 매개변수를 다시 해시하고 저장된 해시 키와 비교합니다.
안타깝게도 모든 매개변수를 해시할 수 있는 것은 아닙니다! 예를 들어 해시할 수 없는 데이터베이스 연결이나 ML 모델을 캐시된 함수에 전달할 수 있습니다. 이 경우 입력 매개변수를 캐싱에서 제외할 수 있습니다. 매개변수 이름 앞에 밑줄(예: _param1)을 붙이기만 하면 캐싱에 사용되지 않습니다. 매개변수가 변경되더라도 다른 모든 매개변수가 일치하면 스트림릿은 캐시된 결과를 반환합니다.
다음은 한 가지 예입니다:
@st.cache_data
def fetch_data(_db_connection, num_rows): # 👈 Don't hash _db_connection
data = _db_connection.fetch(num_rows)
return data
connection = init_connection()
fetch_data(connection, 10)하지만 해시할 수 없는 매개변수를 사용하는 함수를 캐시하려면 어떻게 해야 할까요? 예를 들어 ML 모델을 입력으로 받아 해당 모델의 레이어 이름을 반환하는 함수를 캐시하고 싶을 수 있습니다. 모델이 유일한 입력 매개변수이므로 캐싱에서 제외할 수 없습니다. 이 경우 hash_funcs 매개변수를 사용하여 모델에 대한 사용자 지정 해싱 함수를 지정할 수 있습니다.
4.3.4. The hash_funcs parameter
- Streamlit의 해싱 메커니즘이 매개변수 해싱에 실패하여 UnhashableParamError가 발생하는 경우.
- 매개변수에 대한 Streamlit의 기본 해싱 메커니즘을 재정의하려는 경우.
이러한 각 사례에 대해 예시를 들어 차례로 설명해 보겠습니다.
Example 1: Hashing a custom class
Streamlit은 사용자 정의 클래스를 해시하는 방법을 모릅니다. 사용자 정의 클래스를 캐시된 함수에 전달하면 Streamlit은 UnhashableParamError를 발생시킵니다. 예를 들어, 초기 정수 점수를 받는 사용자 정의 클래스 MyCustomClass를 정의해 보겠습니다. 또한 점수에 승수를 곱하는 캐시 함수 multiply_score를 정의해 보겠습니다:
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data
def multiply_score(obj: MyCustomClass, multiplier: int) -> int:
return obj.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(multiply_score(score, multiplier))이 앱을 실행하면 Streamlit이 MyCustomClass를 해시하는 방법을 모르기 때문에 UnhashableParamError를 발생시키는 것을 볼 수 있습니다:
UnhashableParamError: Cannot hash argument 'obj' (of type __main__.MyCustomClass) in 'multiply_score'.이 문제를 해결하기 위해 hash_funcs 매개변수를 사용하여 Streamlit에 MyCustomClass를 해시하는 방법을 알려줄 수 있습니다. 이를 위해 매개변수 이름을 해시 함수에 매핑하는 사전을 hash_funcs에 전달하면 됩니다. 해시 함수의 선택은 개발자에게 달려 있습니다. 이 경우 사용자 정의 클래스를 입력으로 받아 점수를 반환하는 사용자 정의 해시 함수 hash_func를 정의해 보겠습니다. 점수가 객체의 고유 식별자가 되기를 원하므로 이를 사용하여 객체를 결정론적으로 해시할 수 있습니다:
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
def hash_func(obj: MyCustomClass) -> int:
return obj.my_score # or any other value that uniquely identifies the object
@st.cache_data(hash_funcs={MyCustomClass: hash_func})
def multiply_score(obj: MyCustomClass, multiplier: int) -> int:
return obj.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(multiply_score(score, multiplier))이제 앱을 실행하면 Streamlit이 더 이상 UnhashableParamError를 발생시키지 않고 앱이 예상대로 실행되는 것을 확인할 수 있습니다.
이제 multiply_score가 MyCustomClass의 속성이고 전체 객체를 해시하려는 경우를 고려해 보겠습니다:
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data
def multiply_score(self, multiplier: int) -> int:
return self.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(score.multiply_score(multiplier))이 앱을 실행하면 Streamlit이 'multiply_score'의 'self'(__main__.MyCustomClass 유형) 인수를 해시할 수 없기 때문에 UnhashableParamError를 발생시키는 것을 볼 수 있습니다. 여기서 간단한 해결 방법은 Python의 hash() 함수를 사용하여 객체를 해시하는 것입니다:
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data(hash_funcs={"__main__.MyCustomClass": lambda x: hash(x.my_score)})
def multiply_score(self, multiplier: int) -> int:
return self.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(score.multiply_score(multiplier))위의 해시 함수는 람다 x: hash(x.my_score)로 정의됩니다. 이 함수는 MyCustomClass 인스턴스의 my_score 속성을 기반으로 해시를 생성합니다. my_score가 동일하게 유지되는 한 해시는 동일하게 유지됩니다. 따라서 다시 계산하지 않고도 캐시에서 multiply_score의 결과를 검색할 수 있습니다.
파이썬에 능통한 사람이라면 파이썬의 id() 함수를 사용해 객체를 이렇게 해시하고 싶었을 것입니다:
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data(hash_funcs={"__main__.MyCustomClass": id})
def multiply_score(self, multiplier: int) -> int:
return self.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(score.multiply_score(multiplier))앱을 실행하면, my_score가 변경되지 않았더라도 Streamlit이 매번 multiply_score를 다시 계산하는 것을 확인할 수 있습니다! 의아하시죠? 파이썬에서 id()는 객체의 ID를 반환하며, 이는 평생 동안 객체에 대해 고유하고 일정합니다. 즉, MyCustomClass의 두 인스턴스 간에 my_score 값이 동일하더라도 id()는 이 두 인스턴스에 대해 서로 다른 값을 반환하므로 해시 값이 달라지게 됩니다. 따라서 Streamlit은 이 두 개의 서로 다른 인스턴스에 별도의 캐시 값이 필요한 것으로 간주하여 my_score가 변경되지 않더라도 매번 multiply_score를 다시 계산합니다.
그렇기 때문에 해시 함수로 사용하지 않는 것이 좋으며, 대신 결정론적인 진정한 해시 값을 반환하는 함수를 권장합니다. 즉, 자신이 무엇을 하고 있는지 알고 있다면 id()를 해시 함수로 사용할 수 있습니다. 다만 결과에 유의하세요. 예를 들어, 다른 캐시 함수에 입력 매개변수로 @st.cache_resource 함수의 결과를 전달할 때 id가 올바른 해시 함수가 되는 경우가 많습니다. 그렇지 않으면 해시할 수 없는 객체 유형의 전체 클래스가 있습니다.
Example 2: Hashing a Pydantic model
Pydantic 모델을 해시하려는 다른 예를 살펴보겠습니다:
import streamlit as st
from pydantic import BaseModel
class Person(BaseModel):
name: str
@st.cache_data
def identity(person: Person):
return person
person = identity(Person(name="Lee"))
st.write(f"The person is {person.name}")위에서는 단일 어트리뷰트 이름을 가진 Pydantic의 BaseModel을 사용하여 사용자 정의 클래스 Person을 정의했습니다. 또한 Person의 인스턴스를 인수로 받아 수정 없이 반환하는 ID 함수도 정의했습니다. 이 함수는 결과를 캐시하기 위한 것이므로 동일한 Person 인스턴스로 여러 번 호출하면 다시 계산하지 않고 캐시된 인스턴스를 반환합니다.
그러나 앱을 실행하면 해시할 수 없는 매개변수 오류가 발생합니다: 'identity'에서 인자 'person'('__main__.Person' 유형)을 해시할 수 없습니다. 이는 Streamlit이 Person 클래스를 해시하는 방법을 모르기 때문입니다. 이 문제를 해결하려면 hash_funcs kwarg를 사용하여 Streamlit에 Person을 해시하는 방법을 알려주면 됩니다.
아래 버전에서는 Person 인스턴스를 입력으로 받아 이름 속성을 반환하는 사용자 정의 해시 함수 hash_func를 정의합니다. 이름이 객체의 고유 식별자가 되기를 원하므로 이를 사용하여 객체를 결정론적으로 해시할 수 있습니다:
import streamlit as st
from pydantic import BaseModel
class Person(BaseModel):
name: str
@st.cache_data(hash_funcs={Person: lambda p: p.name})
def identity(person: Person):
return person
person = identity(Person(name="Lee"))
st.write(f"The person is {person.name}")Example 3: Hashing a ML model
즐겨 사용하는 머신 러닝 모델을 캐시된 함수에 전달하고 싶은 경우가 있을 수 있습니다. 예를 들어 사용자가 앱에서 어떤 모델을 선택했는지에 따라 캐시된 함수에 텐서플로우 모델을 전달하고 싶다고 가정해 보겠습니다. 다음과 같이 시도해 볼 수 있습니다:
import streamlit as st
import tensorflow as tf
@st.cache_resource
def load_base_model(option):
if option == 1:
return tf.keras.applications.ResNet50(include_top=False, weights="imagenet")
else:
return tf.keras.applications.MobileNetV2(include_top=False, weights="imagenet")
@st.cache_resource
def load_layers(base_model):
return [layer.name for layer in base_model.layers]
option = st.radio("Model 1 or 2", [1, 2])
base_model = load_base_model(option)
layers = load_layers(base_model)
st.write(layers)위 앱에서 사용자는 두 가지 모델 중 하나를 선택할 수 있습니다. 선택에 따라 앱은 해당 모델을 로드하고 load_layers에 전달합니다. 그러면 이 함수는 모델의 레이어 이름을 반환합니다. 앱을 실행하면 Streamlit이 'load_layers'의 인수 'base_model'(keras.engine.functional.Functional 유형)을 해시할 수 없기 때문에 UnhashableParamError가 발생하는 것을 확인할 수 있습니다.
base_model의 이름 앞에 밑줄을 추가하여 해싱을 비활성화하면 어떤 기본 모델을 선택하든 표시되는 레이어가 동일하다는 것을 알 수 있습니다. 이 미묘한 버그는 기본 모델이 변경될 때 load_layers 함수가 다시 실행되지 않기 때문입니다. 이는 Streamlit이 base_model 인수를 해시하지 않기 때문에 기본 모델이 변경될 때 함수를 다시 실행해야 한다는 사실을 알지 못하기 때문입니다.
이 문제를 해결하기 위해 hash_func kwarg를 사용하여 Streamlit에 base_model 인수를 해시하는 방법을 알려줄 수 있습니다. 아래 버전에서는 사용자 정의 해시 함수 hash_func를 정의합니다: 함수: 람다 x: x.name. 해시 함수 선택은 함수형 객체 또는 모델의 이름 속성이 이를 고유하게 식별한다는 지식에 따라 결정됩니다. 이름 속성이 동일하게 유지되는 한 해시는 동일하게 유지됩니다. 따라서 load_layers 의 결과는 재계산 없이 캐시에서 검색할 수 있습니다.
import streamlit as st
import tensorflow as tf
from keras.engine.functional import Functional
@st.cache_resource
def load_base_model(option):
if option == 1:
return tf.keras.applications.ResNet50(include_top=False, weights="imagenet")
else:
return tf.keras.applications.MobileNetV2(include_top=False, weights="imagenet")
@st.cache_resource(hash_funcs={Functional: lambda x: x.name})
def load_layers(base_model):
return [layer.name for layer in base_model.layers]
option = st.radio("Model 1 or 2", [1, 2])
base_model = load_base_model(option)
layers = load_layers(base_model)
st.write(layers)위의 경우 해시 함수로 hash_funcs={Functional: id}를 사용할 수도 있습니다. 이는 다른 캐시된 함수에 입력 매개변수로 @st.cache_resource 함수의 결과를 전달할 때 id가 올바른 해시 함수인 경우가 많기 때문입니다.
Example 4: Overriding Streamlit's default hashing mechanism
pytz-localized datetime 객체에 대한 Streamlit의 기본 해싱 메커니즘을 재정의하려는 또 다른 예를 살펴보겠습니다:
from datetime import datetime
import pytz
import streamlit as st
tz = pytz.timezone("Europe/Berlin")
@st.cache_data
def load_data(dt):
return dt
now = datetime.now()
st.text(load_data(dt=now))
now_tz = tz.localize(datetime.now())
st.text(load_data(dt=now_tz))지금과 지금_tz가 동일한 <클래스 'datetime.datetime'> 유형임에도 불구하고 Streamlit이 지금_tz를 해시하는 방법을 알지 못해 UnhashableParamError를 발생시키는 것을 보면 놀랄 수도 있습니다. 이 경우, 사용자 정의 해시 함수를 hash_funcs kwarg에 전달하여 날짜/시간 객체에 대한 Streamlit의 기본 해시 메커니즘을 재정의할 수 있습니다:
from datetime import datetime
import pytz
import streamlit as st
tz = pytz.timezone("Europe/Berlin")
@st.cache_data(hash_funcs={datetime: lambda x: x.strftime("%a %d %b %Y, %I:%M%p")})
def load_data(dt):
return dt
now = datetime.now()
st.text(load_data(dt=now))
now_tz = tz.localize(datetime.now())
st.text(load_data(dt=now_tz))이제 NumPy 배열에 대한 Streamlit의 기본 해싱 메커니즘을 재정의하려는 경우를 생각해 보겠습니다. Streamlit은 기본적으로 Pandas와 NumPy 객체를 해시하지만, 이러한 객체에 대해 Streamlit의 기본 해시 메커니즘을 재정의하고 싶은 경우가 있을 수 있습니다.
예를 들어 NumPy 배열을 받아 수정 없이 반환하는 캐시로 장식된 show_data 함수를 만든다고 가정해 보겠습니다. 아래 앱에서는 데이터 = df["str"].unique()(NumPy 배열)가 show_data 함수에 전달됩니다.
import time
import numpy as np
import pandas as pd
import streamlit as st
@st.cache_data
def get_data():
df = pd.DataFrame({"num": [112, 112, 2, 3], "str": ["be", "a", "be", "c"]})
return df
@st.cache_data
def show_data(data):
time.sleep(2) # This makes the function take 2s to run
return data
df = get_data()
data = df["str"].unique()
st.dataframe(show_data(data))
st.button("Re-run")데이터는 항상 동일하므로 show_data 함수는 캐시된 값을 반환할 것으로 예상합니다. 하지만 앱을 실행하고 다시 실행 버튼을 클릭하면 매번 show_data 함수가 다시 실행되는 것을 볼 수 있습니다. 이 동작은 스트림릿의 NumPy 배열에 대한 기본 해싱 메커니즘의 결과라고 가정할 수 있습니다.
이 문제를 해결하기 위해 NumPy 배열을 입력으로 받아 배열의 문자열 표현을 반환하는 사용자 정의 해시 함수 hash_func를 정의해 보겠습니다:
import time
import numpy as np
import pandas as pd
import streamlit as st
@st.cache_data
def get_data():
df = pd.DataFrame({"num": [112, 112, 2, 3], "str": ["be", "a", "be", "c"]})
return df
@st.cache_data(hash_funcs={np.ndarray: str})
def show_data(data):
time.sleep(2) # This makes the function take 2s to run
return data
df = get_data()
data = df["str"].unique()
st.dataframe(show_data(data))
st.button("Re-run")이제 앱을 실행하고 다시 실행 버튼을 클릭하면 show_data 함수가 더 이상 매번 다시 실행되지 않는 것을 확인할 수 있습니다. 여기서 중요한 점은 우리가 선택한 해시 함수는 매우 순진한 선택이었으며 반드시 최선의 선택은 아니었다는 점입니다. 예를 들어 NumPy 배열이 큰 경우 이를 문자열 표현으로 변환하는 데 많은 비용이 들 수 있습니다. 이러한 경우 사용 사례에 적합한 해시 함수가 무엇인지 정의하는 것은 개발자의 몫입니다.
Static elements
버전 1.16.0부터 캐시된 함수에 Streamlit 명령어를 포함할 수 있습니다! 예를 들어 이렇게 할 수 있습니다:
@st.cache_data
def get_api_data():
data = api.get(...)
st.success("Fetched data from API!") # 👈 Show a success message
return data아시다시피 스트림릿은 이전에 캐시되지 않은 경우에만 이 함수를 실행합니다. 이 첫 번째 실행 시 앱에 st.success 메시지가 표시됩니다. 하지만 이후 실행에서는 어떻게 될까요? 여전히 표시됩니다! Streamlit은 캐시된 함수 안에 st. 명령이 있다는 것을 인식하고 첫 번째 실행 중에 저장한 후 이후 실행 시 재생합니다. 정적 요소 재생은 두 캐싱 데코레이터 모두에서 작동합니다. 이 기능을 사용하여 UI의 전체 부분을 캐싱할 수도 있습니다:
@st.cache_data
def show_data():
st.header("Data analysis")
data = api.get(...)
st.success("Fetched data from API!")
st.write("Here is a plot of the data:")
st.line_chart(data)
st.write("And here is the raw data:")
st.dataframe(data)Input widgets
캐시된 함수에서 st.slider 또는 st.text_input과 같은 대화형 입력 위젯을 사용할 수도 있습니다. 위젯 재생은 현재 실험적인 기능입니다. 이 기능을 사용하려면 실험용_allow_widgets 매개변수를 설정해야 합니다:
@st.cache_data(experimental_allow_widgets=True) # 👈 Set the parameter
def get_data():
num_rows = st.slider("Number of rows to get") # 👈 Add a slider
data = api.get(..., num_rows)
return dataStreamlit은 슬라이더를 캐시된 함수에 대한 추가 입력 매개변수처럼 취급합니다. 슬라이더 위치를 변경하면 Streamlit은 이 슬라이더 값에 대한 함수가 이미 캐시되어 있는지 확인합니다. 그렇다면 캐시된 값을 반환합니다. 그렇지 않은 경우 새 슬라이더 값을 사용하여 함수를 다시 실행합니다.
캐시된 함수에서 위젯을 사용하면 앱의 전체 부분을 캐시할 수 있으므로 매우 강력합니다. 하지만 위험할 수도 있습니다! Streamlit은 위젯 값을 추가 입력 파라미터로 취급하기 때문에 과도한 메모리 사용으로 이어질 수 있습니다. 캐시된 함수에 슬라이더가 5개 있고 100MB의 데이터프레임을 반환한다고 가정해 봅시다. 그러면 슬라이더가 반환되는 데이터에 영향을 미치지 않더라도 이 다섯 슬라이더 값의 모든 순열에 대해 캐시에 100MB를 추가합니다! 이렇게 추가하면 캐시가 매우 빠르게 폭발할 수 있습니다. 캐시된 함수에서 위젯을 사용하는 경우 이 제한에 유의하세요. 이 기능은 위젯이 캐시된 반환 값에 직접 영향을 미치는 UI의 분리된 부분에만 사용하는 것이 좋습니다.
Warning
캐시된 기능의 위젯 지원은 실험 단계입니다. 언제든지 예고 없이 변경되거나 제거될 수 있습니다. 신중하게 사용해 주세요!
Note
현재 캐시된 함수에서 지원되지 않는 위젯은 st.file_uploader와 st.camera_input 두 가지입니다. 향후 지원될 수 있습니다. 필요한 경우 언제든지 GitHub 이슈를 열어주세요!
4.3.5. Dealing with large data
앞서 설명했듯이, 데이터 객체는 st.cache_data로 캐시해야 합니다. 하지만 데이터 프레임이나 1억 개가 넘는 행이 있는 배열과 같이 매우 큰 데이터의 경우 속도가 느려질 수 있습니다. 이는 첫 번째 실행 시 반환값을 바이트로 직렬화하고 이후 실행 시 역직렬화하는 st.cache_data의 복사 동작 때문입니다. 두 작업 모두 시간이 걸립니다.
매우 큰 데이터를 처리하는 경우, st.cache_resource를 대신 사용하는 것이 합리적일 수 있습니다. 직렬화/역직렬화를 통해 반환 값의 복사본을 만들지 않으며 거의 즉각적입니다. 하지만 주의할 점은 함수의 반환값을 변경하면(예: 데이터프레임에서 열을 삭제하거나 배열에 값을 설정하는 등) 캐시의 객체가 직접 조작된다는 점입니다. 이로 인해 데이터가 손상되거나 충돌이 발생하지 않도록 해야 합니다. 아래의 변이 및 동시성 문제 섹션을 참조하세요.
열이 4개인 판다 데이터프레임에서 st.cache_data를 벤치마킹한 결과, 1억 행을 초과하면 속도가 느려지는 것을 발견했습니다. 표는 서로 다른 행 수(모두 열이 4개인 경우)에서 두 캐싱 데코레이터의 런타임을 보여줍니다:

4.3.6. Mutation and concurrency issues
위의 섹션에서 캐시된 함수의 반환 객체를 변경할 때 발생하는 문제에 대해 많이 이야기했습니다. 이 주제는 복잡합니다! 하지만 st.cache_data와 st.cache_resource의 동작 차이를 이해하는 데 핵심이 됩니다. 이제 좀 더 자세히 살펴보겠습니다.
먼저 변이와 동시성이 의미하는 바를 명확하게 정의해야 합니다:
- 변이란 캐시된 함수가 호출된 후 해당 함수의 반환값이 변경되는 것을 의미합니다. 예를 들어 다음과 같은 경우입니다:
@st.cache_data def create_list(): l = [1, 2, 3] l = create_list() # 👈 Call the function l[0] = 2 # 👈 Mutate its return value - 동시성이란 여러 세션이 동시에 이러한 변이를 일으킬 수 있다는 의미입니다. Streamlit은 앱에 접속하는 많은 사용자와 세션을 처리해야 하는 웹 프레임워크입니다. 두 사람이 동시에 앱을 보면 두 사람 모두 파이썬 스크립트가 다시 실행되어 캐시된 반환 객체를 동시에 조작할 수 있습니다.
캐시된 반환 객체를 변경하는 것은 위험할 수 있습니다. 앱에서 예외가 발생할 수 있고 심지어 데이터가 손상될 수도 있습니다(앱이 충돌하는 것보다 더 나쁠 수 있습니다!). 아래에서는 먼저 st.cache_data의 복사 동작을 설명하고 돌연변이 문제를 피하는 방법을 보여드리겠습니다. 그런 다음 동시 돌연변이가 어떻게 데이터 손상을 초래할 수 있는지와 이를 방지하는 방법을 보여드리겠습니다.
Copying behavior
st.cache_data는 함수가 호출될 때마다 캐시된 반환 값의 복사본을 생성합니다. 이렇게 하면 대부분의 변이 및 동시성 문제를 방지할 수 있습니다. 이를 더 자세히 이해하기 위해 위의 st.cache_data 섹션의 Uber 차량 공유 예제로 돌아가 보겠습니다. 여기서는 두 가지를 수정합니다:
- st.cache_data 대신 st.cache_resource를 사용하고 있습니다. st.cache_resource는 캐시된 객체의 복사본을 생성하지 않으므로 복사 동작 없이 어떤 일이 발생하는지 확인할 수 있습니다.
- 데이터를 로드한 후 "Lat" 열을 삭제하여 반환된 데이터프레임(in place!)을 조작합니다.
코드는 다음과 같습니다:
@st.cache_resource # 👈 Turn off copying behavior
def load_data(url):
df = pd.read_csv(url)
return df
df = load_data("https://raw.githubusercontent.com/plotly/datasets/master/uber-rides-data1.csv")
st.dataframe(df)
df.drop(columns=['Lat'], inplace=True) # 👈 Mutate the dataframe inplace
st.button("Rerun")실행해보고 어떤 일이 일어나는지 살펴봅시다! 첫 번째 실행은 정상적으로 작동합니다. 하지만 두 번째 실행에서는 예외가 발생합니다: KeyError: "['Lat'] not found in axis" . 왜 이런 문제가 발생할까요? 차근차근 살펴봅시다:
- 처음 실행할 때 Streamlit은 load_data를 실행하고 결과 데이터 프레임을 캐시에 저장합니다. 여기서는 st.cache_resource를 사용하기 때문에 복사본을 생성하지 않고 원본 데이터프레임을 저장합니다.
- 그런 다음 데이터프레임에서 "Lat" 열을 삭제합니다. 이것은 캐시에 저장된 원래 데이터프레임에서 열을 삭제하는 것입니다. 우리는 그것을 조작하고 있습니다!
- 두 번째 실행에서 Streamlit은 캐시에서 정확히 동일한 조작된 데이터 프레임을 반환합니다. 여기에는 더 이상 "Lat" 열이 없습니다! 따라서 df.drop을 호출하면 예외가 발생합니다. pandas는 존재하지 않는 열을 삭제할 수 없습니다.
st.cache_data의 복사 동작은 이러한 종류의 돌연변이 오류를 방지합니다. 변이는 특정 복사본에만 영향을 미칠 수 있으며 캐시의 기본 객체에는 영향을 미치지 않습니다. 다음 재실행은 데이터프레임의 변경되지 않은 자체 복사본을 가져옵니다. 직접 시도해 보려면 위의 st.cache_resource를 st.cache_data로 바꾸기만 하면 모든 것이 작동하는 것을 확인할 수 있습니다.
이러한 복사 동작으로 인해 직렬화 가능한 객체를 반환하는 모든 데이터 변환 및 계산을 캐시하는 데는 st.cache_data를 사용하는 것이 좋습니다.
Concurrency issues
이제 여러 사용자가 동시에 캐시에 있는 객체를 변경할 때 어떤 일이 발생할 수 있는지 살펴보겠습니다. 목록을 반환하는 함수가 있다고 가정해 보겠습니다. 다시 말하지만, 복사본을 만들지 않도록 st.cache_resource를 사용하여 캐시하고 있습니다:
@st.cache_resource
def create_list():
l = [1, 2, 3]
return l
l = create_list()
first_list_value = l[0]
l[0] = first_list_value + 1
st.write("l[0] is:", l[0])사용자 A가 앱을 실행한다고 가정해 보겠습니다. 다음과 같은 출력이 표시됩니다:
l[0] is: 2다른 사용자 B가 앱을 바로 방문한다고 가정해 보겠습니다. 사용자 A와는 달리 다음과 같은 출력이 표시됩니다:
l[0] is: 3이제 사용자 A가 사용자 B의 바로 뒤에 앱을 다시 실행하면 다음과 같은 결과가 표시됩니다:
l[0] is: 4여기서 무슨 일이 일어나고 있나요? 모든 출력이 다른 이유는 무엇인가요?
- 사용자 A가 앱을 방문하면 create_list()가 호출되고 목록 [1, 2, 3]이 캐시에 저장됩니다. 그런 다음 이 목록이 사용자 A에게 반환되고 목록의 첫 번째 값인 1이 first_list_value 에 할당되고 l[0]이 2로 변경됩니다.
- 사용자 B가 앱을 방문하면 create_list()는 캐시에서 변경된 목록을 반환합니다:[2, 2, 3]. 목록의 첫 번째 값인 2가 first_list_value에 할당되고 l[0]이 3으로 변경됩니다.
- 사용자 A가 앱을 다시 실행하면 create_list()는 변경된 목록을 다시 반환합니다:[3, 2, 3]. 목록의 첫 번째 값인 3이 first_list_value에 할당되고 l[0]이 4로 변경됩니다.
생각해보면 이해가 되는 부분입니다. 사용자 A와 B는 동일한 목록 객체(캐시에 저장된 객체)를 사용합니다. 그리고 목록 객체가 변경되므로 사용자 A의 목록 객체 변경 사항이 사용자 B의 앱에도 반영됩니다.
그렇기 때문에 특히 여러 사용자가 동시에 앱에 액세스하는 경우 st.cache_resource로 캐시된 객체를 변경할 때 주의해야 합니다. st.cache_resource 대신 st.cache_data를 사용했다면 앱은 각 사용자에 대한 목록 개체를 복사했을 것이고, 위의 예제는 예상대로 작동하여 사용자 A와 B가 모두 볼 수 있었을 것입니다:
l[0] is: 2
Note
이 장난감 예제는 무해해 보일 수 있습니다. 하지만 데이터 손상은 매우 위험할 수 있습니다! 여기서 대형 은행의 재무 기록을 다루고 있다고 상상해 보세요. 누군가 잘못된 캐싱 데코레이터를 사용했다고 해서 계좌에 있는 돈이 줄어든 채로 깨어나고 싶지는 않겠죠 😉.
4.4. Migrating from st.cache
위에서 설명한 캐싱 명령어는 Streamlit 1.18.0에서 도입되었습니다. 그 전에는 포괄적인 명령어인 st.cache가 하나 있었습니다. 이 명령어를 사용하면 종종 혼란스럽고 이상한 예외가 발생하며 속도가 느렸습니다. 그래서 1.18.0에서는 st.cache를 새로운 명령어로 대체했습니다(이 블로그 게시물에서 자세히 읽어보세요). 새로운 명령어는 데이터와 리소스를 캐시하는 보다 직관적이고 효율적인 방법을 제공하며, 모든 새로운 개발에서 st.cache를 대체할 예정입니다.
앱에서 여전히 st.cache를 사용하고 있다면 절망하지 마세요! 마이그레이션에 대한 몇 가지 참고 사항을 알려드립니다:
- 앱에서 st.cache를 사용하는 경우 Streamlit에 사용 중단 경고가 표시됩니다.
- 곧 st.cache를 제거하지 않을 예정이므로 2년 된 앱이 깨질까 걱정할 필요는 없습니다. 하지만 앞으로 새로운 명령어를 사용해 보시면 훨씬 덜 짜증날 것입니다!
- 대부분의 경우 새 명령어로 코드를 쉽게 전환할 수 있습니다. st.cache_data 또는 st.cache_resource를 사용할지 결정하려면 사용할 캐싱 데코레이터 결정하기를 참조하세요. 또한 Streamlit은 일반적인 사용 사례를 인식하여 사용 중단 경고에 힌트를 표시합니다.
- 몇 가지 예외를 제외하고 st.cache의 대부분의 매개변수는 새 명령어에도 있습니다:
- allow_output_mutation이 더 이상 존재하지 않습니다. 안전하게 삭제할 수 있습니다. 다만 사용 사례에 맞는 캐싱 명령을 사용해야 합니다.
- suppress_st_warning 은 더 이상 존재하지 않습니다. 안전하게 삭제할 수 있습니다. 이제 캐시된 함수에 스트림라이트 명령어를 포함할 수 있으며 재생됩니다. 캐시된 함수 내에서 위젯을 사용하려면 실험적 허용 위젯 = True로 설정하세요. 예시는 입력 위젯을 참조하세요.
5. Session State
5.1. What is State?
브라우저 탭에서 스트림릿 앱에 대한 액세스를 세션으로 정의합니다. Streamlit 서버에 연결되는 각 브라우저 탭에 대해 새 세션이 생성됩니다. Streamlit은 사용자가 앱과 상호작용할 때마다 스크립트를 위에서 아래로 재실행합니다. 각 재실행은 백지 상태에서 이루어지며, 실행 간에 변수가 공유되지 않습니다.
세션 상태는 각 사용자 세션에 대해 재실행 간에 변수를 공유하는 방법입니다. 스트림릿은 상태를 저장하고 유지하는 기능 외에도 콜백을 사용하여 상태를 조작하는 기능도 제공합니다. 세션 상태는 다중 페이지 앱 내의 여러 페이지에서도 유지됩니다.
이 가이드에서는 상태 저장 카운터 앱을 구축할 때 세션 상태와 콜백의 사용법을 설명합니다.
세션 상태 및 콜백 API에 대한 자세한 내용은 세션 상태 API 참조 가이드를 참조하세요.
또한 스트림릿 개발자 지원자인 마리사 스미스 박사의 세션 상태 기본 튜토리얼 동영상을 통해 시작해보세요:
5.2. Build a Counter
counter.py 스크립트를 호출해 보겠습니다. 카운트 변수를 초기화하고 카운트 변수에 저장된 값을 증가시키는 버튼이 있습니다:
import streamlit as st
st.title('Counter Example')
count = 0
increment = st.button('Increment')
if increment:
count += 1
st.write('Count = ', count)위 앱에서 증분 버튼을 몇 번을 눌러도 카운트는 1로 유지됩니다. 그 이유를 알아봅시다:위 앱에서 증분 버튼을 몇 번을 눌러도 카운트는 1로 유지됩니다. 그 이유를 알아봅시다:
- 증분 버튼을 누를 때마다 Streamlit은 카운터 파이를 위에서 아래로 다시 실행하고, 실행할 때마다 카운트는 0으로 초기화됩니다.
- 이후 증분을 누르면 1에 0을 더하므로 증분을 몇 번을 누르더라도 카운트=1이 됩니다.
나중에 살펴보겠지만, 카운트를 세션 상태 변수로 저장하면 이 문제를 피할 수 있습니다. 이렇게 하면 앱이 재실행되는 동안 세션 상태 변수에 저장된 값을 유지해야 한다는 것을 Streamlit에 알릴 수 있습니다.
세션 상태를 사용하기 위한 API에 대해 좀 더 알아봅시다.
5.3. Initialization
세션 상태 API는 파이썬 딕셔너리와 매우 유사한 필드 기반 API를 따릅니다:
import streamlit as st
# Check if 'key' already exists in session_state
# If not, then initialize it
if 'key' not in st.session_state:
st.session_state['key'] = 'value'
# Session State also supports the attribute based syntax
if 'key' not in st.session_state:
st.session_state.key = 'value'5.4. Reads and updates
st.write 에 항목을 전달하여 세션 상태의 항목 값을 읽습니다:
import streamlit as st
if 'key' not in st.session_state:
st.session_state['key'] = 'value'
# Reads
st.write(st.session_state.key)
# Outputs: value세션 상태의 항목에 값을 할당하여 업데이트합니다:
import streamlit as st
if 'key' not in st.session_state:
st.session_state['key'] = 'value'
# Updates
st.session_state.key = 'value2' # Attribute API
st.session_state['key'] = 'value2' # Dictionary like API초기화되지 않은 변수에 액세스하면 Streamlit은 예외를 던집니다:
import streamlit as st
st.write(st.session_state['value'])
# Throws an exception!
... 나머지 내용은 나중에 다시 보는게 나을듯