

목차
0. 관련 글 목록
(1) [ML4T] Machine Learning for Trading: From Idea to Execution
(2) [ML4T] 미국 주식 데이터 수집하기 - 주가, 거래량, 재무 데이터
이 글은 퀀트 투자를 위한 머신러닝 딥러닝 알고리즘 트레이딩 2/e 7장의 내용을 바탕으로 작성되었습니다.
https://github.com/stefan-jansen/machine-learning-for-trading
GitHub - stefan-jansen/machine-learning-for-trading: Code for Machine Learning for Algorithmic Trading, 2nd edition.
Code for Machine Learning for Algorithmic Trading, 2nd edition. - GitHub - stefan-jansen/machine-learning-for-trading: Code for Machine Learning for Algorithmic Trading, 2nd edition.
github.com
1. 들어가며
7장은 선형 모델을 통한 리스크 팩터 학습, 자산 수익률 예측에 관한 내용을 다루고 있다. 7장의 내용 중에서 이번 스터디를 통해 새롭게 알게 된 파마-프렌치 5팩터 모델, 파마-맥베스 회귀분석에 관해 정리해보려고 한다.
2. 파마-프렌치 5팩터 모델(Fama-French 5 factor model)
팩터 모델은(factor model)은 자산의 수익률과 이 수익률을 이끌어 내는 리스크 원천 간의 관계를 계량화하기 위해 사용된다. 팩터 모델은 자본 자산 가격 결정 모델(Capital Asset Pricing Model; CAPM)에서 출발한다. CAPM은 무위험 이자율(Rf, ex.국채 금리) 대비 전체 시장의 초과 기대 수익률(Rm-Rf)을 독립변수로 개별 자산의 기대 수익률(Ri)을 종속변수로 하는 단순 선형 회귀 모형(simple linear regression model)으로 볼 수 있다.
$$R_i= \alpha_i + Rf + \beta_i(Rm-Rf)$$
실제 적용시에는 개별 자산의 경우도 초과수익률을 계산한 다음 회귀 모형을 적합하기 때문에 무위험 수익률을 좌변으로 넘겨서 아래와 같이 식을 다시 쓸수 있다.
$$R_i-Rf= \alpha_i + \beta_i(Rm-Rf)$$
CAPM을 통해 전체 시장의 움직임 대비 개별 자산이 얼마나 민감하게 움직이는지 알아볼 수 있지만 시장 초과수익률로는 설명되지 않는 현상들이 자주 관측되기 시작하면서 자산 수익률을 설명하기 위한 새로운 팩터를 찾는 작업이 이루어 졌는데, 유진 파마(Eugene Fama)1와 케네스 프렌치(Kenneth French)가 제안한 파마-프렌치 3 팩터 모델(1993)2, 파마-프렌치 5 팩터 모델(2014)이 대표적이다. 파마-프렌치 3 팩터 모델은 CAPM에서 사용한 리스크 원천에 기업의 상대적 규모(relative size)와 가치(value)를 추가한 것이고, 5 팩터 모델은 여기에 기업 이익(firm profitability)과 투자 수준(level of investment)을 포함하여 확장한 것이다. 파마-프렌치 3 팩터 모델은 시장의 초과 수익을 나타내는 베타가 유의한 팩터가 아니며, 그보다는 기업 규모와 가치지표를 사용하는 것이 자산 수익률 예측에 효과적이라는 것을 밝혔다고 한다. 결과적으로는 '시가총액이 작은 저평가된(PBR이 낮은) 가치주를 사는 것이 좋다'라는게 논문이 말하고자 하는 것이었다.
| Concept | Label | Name | Description |
| 기업 규모 | SMB | Small Minus Big | (average return on the 9 small stock portfolios) - (average return on the 9 big stock portfolios) |
| 가치 | HML | High Minus Low | (average return on the 2 value portfolios) - (average return on the 2 growth portfolios) |
| 영업 수익성 | RMW | Robust Minus Weak | (average return on the 2 robust operating profitability portfolios) - (average return on the 2 weak operating profitability portfolios) |
| 투자 | CMA | Conservative Minus Aggressive | (average return on the 2 conservative investment portfolios) - (average return on the 2 aggressive investment portfolios) |
| 시장 | Rm-Rf | Excess return on the market | (value-weight return of all firms incorporated in the US and listed on the NYSE, AMEX, or NASDAQ at the beginning of month t with 'good' data for t) - (the one-month Treasury bill rate) |
- 기업 규모: 시가총액
- 가치: 주식의 장부가치(Book value = 순자산 = 자본)을 시가총액으로 나눈 값 = 1/PBR
- 영업 수익성(OP): 매출에서 비용을 뺀 금액
- 투자: 투자를 얼마나 보수적/공격적으로 하는지
위의 표는 각 팩터에 대한 책에 제시된 설명인데 SMB와 HML에 대한 설명이 논문에서의 설명과는 조금 다르다. 논문에서 SMB, HML 팩터를 계산한 방식은 글 마지막에 첨부한 파이썬으로 배우는 포트폴리오 - 6.3 파마-프렌치 3요인 모델에 잘 설명이 되어 있다.
SMB와 HML 포트폴리오를 구성하는 방법은 다음과 같다. 기업의 시가총액 기준으로 상위 50%와 하위 50%에 속하는 기업들로 두 개의 포트폴리오(Big, Small)를 구성한다. 그리고 장부가/시장가 비율 기준으로 상위 30%, 중위 40%, 하위 30%에 속하는 기업들로 세 개의 포트폴리오(Value, Neutral, Growth)를 구성한다. 이렇게 기업 규모 기준 두 그룹과 장부가/시장가 기준 세 그룹을 서로 교차해 여섯 개의 기업 규모-장부가/시장가(BV, BN, BG, SV, SN, SG)를 구성한 후, SMB는 1/3(SV + SN + SG) - 1/3(BV + BN + BG), HML은 1/2(SV + BV) - 1/2(SG + BG)로 계산한다.
...
SMB 계산에는 여섯 개의 포트폴리오가 필요하다. BE/ME(가치주, 성장주, 중립주)와 시가총액의 크기(소형, 대형)로 나눠 소형가치주, 소형중립주, 소형성장주와 대형가치주, 대형중립주, 대형성장주다. HML은 대형가치주와 소형가치주의 수익률 평균에서 대형성장주와 소형성장주의 수익률 평균을 뺀 것이다.
결과적으로 파마-프렌치 5 팩터 모델은 아래와 같이 쓸 수 있다.
$$R_i-Rf= \alpha_i + \beta_i(Rm-Rf)+s_{i}SMB+h_{i}HML+r_{i}RMW+c_{i}CMA$$
파마-프렌치 팩터 모델에 관한 리서치 결과는 케네스 프렌치의 웹페이지에 지속적으로 업데이트 되고 있다.
3. 파마-맥베스 회귀분석(Fama-MacBeth regression)
자산 수익률을 종속변수, 5개의 팩터를 독립변수로 하는 다중회귀분석을 수행하여 파마-프렌치 팩터 모델을 만들 수도 있다. 하지만 일정기간 동안 여러 자산에 대해 추정을 수행해야 하는 팩터 모델의 특성상 다중회귀모형의 가정을 위반3할 가능성이 높다. 잔차의 상관관계로 유발되는 추론상의 문제4를 해결하기 위해 파마(Fama)와 맥베스(MacBeth)는 팩터에 대한 수익률의 횡단면 회귀 분석을 위한 2-step 방법론을 제안하였다. 파마-맥베스 회귀분석(Fama-MacBeth regression)은 데이터의 각 관측 시점마다 횡단면 회귀분석(cross-sectional regression)을 실시하여 얻은 회귀계수 추정치들의 집합으로부터 각 회귀계수들의 시계열 평균 표준오차, 이에 기반하는 검정통계량(t-statistic)을 얻는 추정방식이다.5
[Step1] 각 자산에 대해 M개의 팩터를 독립변수, N개의 자산 포트폴리오의 수익률을 종속변수로 하는 회귀모형 적합
$$R_{1,t}=\beta_0 + \beta_{1,F_1}F_{1,t}+ \beta_{1, F_2}F_{2,t}+ \cdots + \beta_{1, F_M}F_{M,t}+\epsilon_{1,t}$$$$R_{2,t}=\beta_0 + \beta_{2,F_1}F_{1,t}+ \beta_{2, F_2}F_{2,t}+ \cdots + \beta_{2, F_M}F_{M,t}+\epsilon_{2,t}$$$$\cdots$$$$R_{N,t}=\beta_0 + \beta_{N,F_1}F_{1,t}+ \beta_{N, F_2}F_{2,t}+ \cdots + \beta_{N, F_M}F_{M,t}+\epsilon_{n,t}$$
[Step2] Step1에서 구한 회귀계수(\(\hat{\beta}\))를 독립변수, 각 시점의 포트폴리오 수익률(\(R_{i, t}(i=1,\cdots,n)\))을 종속변수로 하는 회귀모형 적합
$$R_{i,1} = \lambda_{1,0}+\lambda_{1,1}\hat{\beta}_{i, F_1}+\lambda_{1,2}\hat{\beta}_{i, F_2}+ \cdots + \lambda_{1,M}\hat{\beta}_{i, F_M} + \epsilon_{i,1}$$$$R_{i,2} = \lambda_{2,0}+\lambda_{2,1}\hat{\beta}_{i, F_1}+\lambda_{2,2}\hat{\beta}_{i, F_2}+ \cdots + \lambda_{2,M}\hat{\beta}_{i, F_M} + \epsilon_{i,2}$$$$\cdots$$$$R_{i,T} = \lambda_{T,0}+\lambda_{T,1}\hat{\beta}_{i, F_1}+\lambda_{T,2}\hat{\beta}_{i, F_2}+ \cdots + \lambda_{T,M}\hat{\beta}_{i, F_M} + \epsilon_{i,T}$$
[Step1]은 N개의 자산에 대해 각각 회귀모델을 적합시키는 것이고, [Step2]는 T개의 시점에 대해 각각 회귀모델을 적합시키는 것이다. [Step2]의 결과로 나오는 회귀계수 행렬 \(\hat{\lambda}_{T \times M}\)을 시간축 t에 대해 평균을 취한 각 팩터의 계수값을 각 팩터에 대한 최종적인 회귀계수 추정값으로 사용한다.
4. 파이썬 구현
이제 파마-맥베스 회귀분석을 이용하여 파마-프렌치 5 팩터 모델을 파이썬 코드를 통해 구현해보자. 파마와 프렌치는 자신들의 웹사이트에 리스크 팩터와 17개 산업군에 대한 포트폴리오 데이터를 제공하고 있고, pandas-datareader를 통해 이 데이터를 불러올 수 있다. 예제 코드에서는 2000년~2020년의 데이터를 불러와서 사용하였다. 수익률은 월단위로 제공되어 불러온 데이터에는 21x12=252개의 데이터포인트가 존재한다.
17개 산업군에 대한 세부사항은 다음 첨부파일을 참고
import pandas as pd
import numpy as np
from statsmodels.api import OLS, add_constant
import pandas_datareader.data as web
from linearmodels.asset_pricing import LinearFactorModel
import matplotlib.pyplot as plt
import seaborn as sns# 2000~2020 월별 수익률
ff_factor = 'F-F_Research_Data_5_Factors_2x3'
ff_factor_data = web.DataReader(ff_factor, 'famafrench', start='2000', end='2020-12')[0]
ff_factor_data.info()
<class 'pandas.core.frame.DataFrame'>
PeriodIndex: 252 entries, 2000-01 to 2020-12
Freq: M
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Mkt-RF 252 non-null float64
1 SMB 252 non-null float64
2 HML 252 non-null float64
3 RMW 252 non-null float64
4 CMA 252 non-null float64
5 RF 252 non-null float64
dtypes: float64(6)
memory usage: 13.8 KB# 17개 산업군의 월별 포트폴리오 수익률
ff_portfolio = '17_Industry_Portfolios'
ff_portfolio_data = web.DataReader(ff_portfolio, 'famafrench', start='2000', end='2020-12')[0]
ff_portfolio_data.info()
<class 'pandas.core.frame.DataFrame'>
PeriodIndex: 252 entries, 2000-01 to 2020-12
Freq: M
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Food 252 non-null float64
1 Mines 252 non-null float64
2 Oil 252 non-null float64
3 Clths 252 non-null float64
4 Durbl 252 non-null float64
5 Chems 252 non-null float64
6 Cnsum 252 non-null float64
7 Cnstr 252 non-null float64
8 Steel 252 non-null float64
9 FabPr 252 non-null float64
10 Machn 252 non-null float64
11 Cars 252 non-null float64
12 Trans 252 non-null float64
13 Utils 252 non-null float64
14 Rtail 252 non-null float64
15 Finan 252 non-null float64
16 Other 252 non-null float64
dtypes: float64(17)
memory usage: 35.4 KB# 포트폴리오 수익률 - 무위험 수익률 = 초과 수익률
ff_portfolio_data = ff_portfolio_data.sub(ff_factor_data.RF, axis=0)
# 무위험 수익률 변수를 제외한 5개 팩터 변수만 남김
ff_factor_data = ff_factor_data.drop('RF', axis=1)
ff_factor_data.info()
<class 'pandas.core.frame.DataFrame'>
PeriodIndex: 252 entries, 2000-01 to 2020-12
Freq: M
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Mkt-RF 252 non-null float64
1 SMB 252 non-null float64
2 HML 252 non-null float64
3 RMW 252 non-null float64
4 CMA 252 non-null float64
dtypes: float64(5)
memory usage: 11.8 KB# Step 1: Factor Exposures
betas = []
for industry in ff_portfolio_data:
step1 = OLS(endog=ff_portfolio_data.loc[ff_factor_data.index, industry], # 종속변수
exog=add_constant(ff_factor_data) # 독립변수
).fit()
betas.append(step1.params.drop('const'))
betas = pd.DataFrame(betas,
columns=ff_factor_data.columns,
index=ff_portfolio_data.columns)
betas.info()
<class 'pandas.core.frame.DataFrame'>
Index: 17 entries, Food to Other
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Mkt-RF 17 non-null float64
1 SMB 17 non-null float64
2 HML 17 non-null float64
3 RMW 17 non-null float64
4 CMA 17 non-null float64
dtypes: float64(5)
memory usage: 1.4+ KBbetas
# Step 2: Risk Premia
lambdas = []
for period in ff_portfolio_data.index:
step2 = OLS(endog=ff_portfolio_data.loc[period, betas.index], # 종속변수
exog=betas # 독립변수
).fit()
lambdas.append(step2.params)
lambdas = pd.DataFrame(lambdas,
index=ff_portfolio_data.index,
columns=betas.columns.tolist())
lambdas.info()
<class 'pandas.core.frame.DataFrame'>
PeriodIndex: 252 entries, 2000-01 to 2020-12
Freq: M
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Mkt-RF 252 non-null float64
1 SMB 252 non-null float64
2 HML 252 non-null float64
3 RMW 252 non-null float64
4 CMA 252 non-null float64
dtypes: float64(5)
memory usage: 33.8 KBlambdas
lambdas.mean()
Mkt-RF 0.697643
SMB -0.616402
HML -0.160462
RMW 0.629483
CMA 0.009336
dtype: float64lambdas.mean().sort_values().plot.barh(figsize=(12, 4))
sns.despine()
plt.tight_layout();
t = lambdas.mean().div(lambdas.std())
t
Mkt-RF 0.149588
SMB -0.085795
HML -0.034590
RMW 0.128289
CMA 0.001396
dtype: float64아래는 2단계 추정의 결과로 산출된 계수 값들을 2년 단위로 이동평균을 계산하여 그래프를 그린 것이다. 계수 추정치가 시간의 흐름에 따라 크게 변하지는 않는지 확인하기 위한 것으로 보면 된다.
window = 24 # months
lambdas.rolling(window).mean().dropna().plot(lw=2,
figsize=(14, 7),
subplots=True,
sharey=True)
sns.despine()
plt.tight_layout()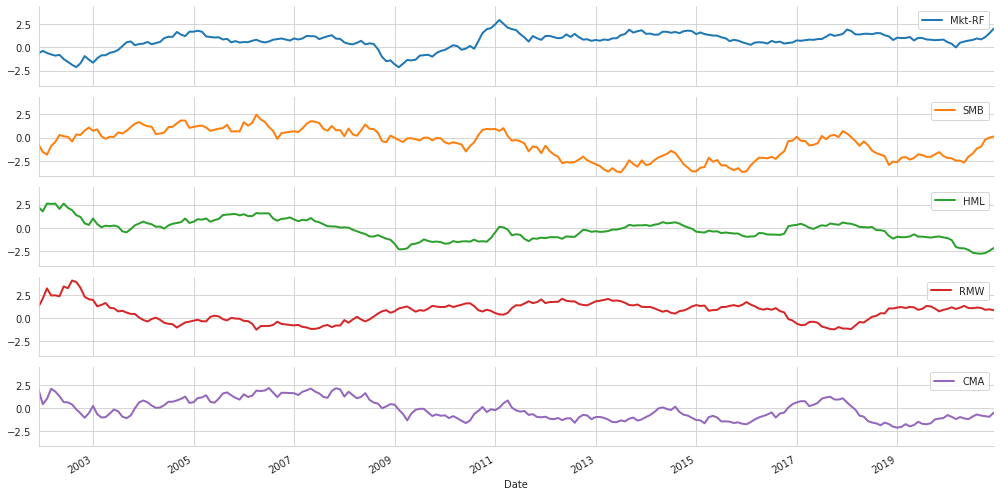
LinearModels 라이브러리는 statsmodels 라이브러리를 확장하여 패널 데이터를 다루기 위한 다양한 모델을 제공하고 파마-맥베스 회귀 모형도 제공한다. 위에서 2-step으로 직접구현한 결과와 동일한 계수 추정치를 얻을 수 있다.
mod = LinearFactorModel(portfolios=ff_portfolio_data,
factors=ff_factor_data)
res = mod.fit()
print(res)
LinearFactorModel Estimation Summary
================================================================================
No. Test Portfolios: 17 R-squared: 0.6808
No. Factors: 5 J-statistic: 14.223
No. Observations: 252 P-value 0.2867
Date: Sat, Nov 20 2021 Distribution: chi2(12)
Time: 12:31:13
Cov. Estimator: robust
Risk Premia Estimates
==============================================================================
Parameter Std. Err. T-stat P-value Lower CI Upper CI
------------------------------------------------------------------------------
Mkt-RF 0.6976 0.3033 2.3004 0.0214 0.1032 1.2921
SMB -0.6164 0.5427 -1.1358 0.2560 -1.6801 0.4473
HML -0.1605 0.3537 -0.4537 0.6500 -0.8536 0.5327
RMW 0.6295 0.3563 1.7666 0.0773 -0.0689 1.3279
CMA 0.0093 0.5795 0.0161 0.9871 -1.1265 1.1452
==============================================================================
Covariance estimator:
HeteroskedasticCovariance
See full_summary for complete results
파마-맥베스의 연구에서는 시장의 초과 수익률 베타의 효과가 없고 사이즈(SMB), 가치(HML) 팩터의 효과가 있다는 것을 보여주었는데 분석 기간의 차이로 인한 것인지 2000~2020년의 데이터로 분석한 결과에서는 Mkt-RF는 유의한 팩터이고, SMB, HML은 유의하지 않은 팩터로 나타났다. Mkt-RF와 RMW만 유의한 팩터로 나타났는데, 영업이익이 꾸준하게 나오고 모멘텀이 좋은(Mkt-RF는 모멘텀 팩터로 볼 수 있다고 함) 자산에 투자하는 것이 좋다라고 해석해볼 수 있을 것 같다. 2000년~2020년까지 어떤 주식들이 많이 올랐는지 생각해보면 어느 정도 말이 되는 것 같기도 하다. 구글, 페이스북, 애플, 마이크로소프트 등등. 이렇게 분석 기간에 따른 차이 효과를 보정하기 위해 여러 기간의 데이터를 섞어서 백테스팅을 하는 경우가 많다고 한다.
full_summary를 프린트해보면 각각의 산업군에 대한 계수 추정치가 나오는데 산업군별로 유의한 팩터들이 다르게 나타나는 것을 볼 수 있다. 팩터들 중에서 Mkt-RF만이 모든 산업군에 걸쳐 유의한 팩터로 나타났는데, 2000년대 들어서 시장 모멘텀이 자산 수익률을 설명하는데 있어서 다른 팩터에 비해 중요한 요소가 되었다고 볼 수 있을 것 같다.
print(res.full_summary)
LinearFactorModel Estimation Summary
================================================================================
No. Test Portfolios: 17 R-squared: 0.6808
No. Factors: 5 J-statistic: 14.223
No. Observations: 252 P-value 0.2867
Date: Sat, Nov 20 2021 Distribution: chi2(12)
Time: 12:31:13
Cov. Estimator: robust
Risk Premia Estimates
==============================================================================
Parameter Std. Err. T-stat P-value Lower CI Upper CI
------------------------------------------------------------------------------
Mkt-RF 0.6976 0.3033 2.3004 0.0214 0.1032 1.2921
SMB -0.6164 0.5427 -1.1358 0.2560 -1.6801 0.4473
HML -0.1605 0.3537 -0.4537 0.6500 -0.8536 0.5327
RMW 0.6295 0.3563 1.7666 0.0773 -0.0689 1.3279
CMA 0.0093 0.5795 0.0161 0.9871 -1.1265 1.1452
Food Coefficients
==============================================================================
Parameter Std. Err. T-stat P-value Lower CI Upper CI
------------------------------------------------------------------------------
alpha -0.0097 0.1286 -0.0756 1.0602 -0.2618 0.2423
Mkt-RF 0.6447 0.0441 14.624 0.0000 0.5583 0.7311
SMB -0.0975 0.0694 -1.4057 1.8402 -0.2335 0.0385
HML -0.0529 0.0778 -0.6807 1.5040 -0.2053 0.0995
RMW 0.4435 0.0688 6.4443 0.0000 0.3086 0.5784
CMA 0.3983 0.1088 3.6621 0.0003 0.1851 0.6115
Mines Coefficients
==============================================================================
alpha 0.2578 0.2615 0.9860 0.3241 -0.2546 0.7703
Mkt-RF 1.0971 0.1255 8.7402 0.0000 0.8511 1.3431
SMB 0.5441 0.1568 3.4711 0.0005 0.2369 0.8514
HML -0.0489 0.1827 -0.2676 1.2110 -0.4069 0.3092
RMW 0.4567 0.2224 2.0537 0.0400 0.0208 0.8925
CMA 0.3523 0.2933 1.2012 0.2297 -0.2225 0.9271
Oil Coefficients
==============================================================================
alpha -0.3081 0.3006 -1.0250 1.6946 -0.8973 0.2811
Mkt-RF 1.0900 0.1049 10.395 0.0000 0.8845 1.2955
SMB 0.2674 0.1311 2.0397 0.0414 0.0105 0.5243
HML 0.3203 0.1878 1.7054 0.0881 -0.0478 0.6885
RMW 0.5631 0.1858 3.0307 0.0024 0.1989 0.9272
CMA 0.1068 0.2231 0.4785 0.6323 -0.3305 0.5441
Clths Coefficients
==============================================================================
alpha 0.2427 0.1815 1.3373 0.1811 -0.1130 0.5984
Mkt-RF 1.1220 0.0695 16.153 0.0000 0.9858 1.2581
SMB 0.2910 0.1097 2.6533 0.0080 0.0760 0.5060
HML 0.3071 0.1095 2.8055 0.0050 0.0926 0.5216
RMW 0.6851 0.1162 5.8968 0.0000 0.4574 0.9128
CMA -0.1721 0.1638 -1.0507 1.7066 -0.4932 0.1489
Durbl Coefficients
==============================================================================
alpha -0.0413 0.2952 -0.1399 1.1112 -0.6199 0.5374
Mkt-RF 1.2069 0.0569 21.216 0.0000 1.0954 1.3183
SMB 0.4881 0.0848 5.7565 0.0000 0.3219 0.6543
HML 0.1314 0.0937 1.4025 0.1608 -0.0522 0.3151
RMW 0.4728 0.0960 4.9251 0.0000 0.2847 0.6610
CMA 0.2115 0.1436 1.4726 0.1409 -0.0700 0.4931
Chems Coefficients
==============================================================================
alpha -0.1812 0.2048 -0.8847 1.6237 -0.5825 0.2202
Mkt-RF 1.2233 0.0617 19.828 0.0000 1.1024 1.3443
SMB 0.1207 0.0763 1.5819 0.1137 -0.0288 0.2702
HML 0.2699 0.1100 2.4530 0.0142 0.0543 0.4856
RMW 0.4490 0.1048 4.2865 0.0000 0.2437 0.6543
CMA -0.0102 0.1522 -0.0668 1.0532 -0.3085 0.2882
Cnsum Coefficients
==============================================================================
alpha -0.0442 0.1322 -0.3344 1.2619 -0.3034 0.2150
Mkt-RF 0.6802 0.0418 16.288 0.0000 0.5984 0.7621
SMB -0.2978 0.0872 -3.4148 1.9994 -0.4687 -0.1269
HML -0.1846 0.0835 -2.2117 1.9730 -0.3482 -0.0210
RMW 0.2155 0.0885 2.4353 0.0149 0.0421 0.3890
CMA 0.5916 0.1290 4.5869 0.0000 0.3388 0.8445
Cnstr Coefficients
==============================================================================
alpha 0.1441 0.2284 0.6310 0.5281 -0.3035 0.5917
Mkt-RF 1.1348 0.0571 19.886 0.0000 1.0229 1.2466
SMB 0.3169 0.0818 3.8728 0.0001 0.1565 0.4773
HML 0.2392 0.0941 2.5411 0.0110 0.0547 0.4237
RMW 0.3684 0.1040 3.5440 0.0004 0.1647 0.5722
CMA -0.0338 0.1472 -0.2300 1.1819 -0.3223 0.2546
Steel Coefficients
==============================================================================
alpha -0.2861 0.1912 -1.4963 1.8654 -0.6609 0.0887
Mkt-RF 1.5554 0.0936 16.621 0.0000 1.3720 1.7388
SMB 0.4300 0.1254 3.4288 0.0006 0.1842 0.6758
HML 0.1641 0.1470 1.1166 0.2642 -0.1240 0.4523
RMW -0.0631 0.1517 -0.4160 1.3226 -0.3604 0.2342
CMA 0.0172 0.2168 0.0795 0.9367 -0.4077 0.4421
FabPr Coefficients
==============================================================================
alpha 0.1755 0.1633 1.0750 0.2824 -0.1445 0.4956
Mkt-RF 1.1267 0.0608 18.536 0.0000 1.0076 1.2459
SMB 0.3414 0.0884 3.8623 0.0001 0.1682 0.5147
HML 0.0898 0.0852 1.0530 0.2924 -0.0773 0.2568
RMW 0.6146 0.1099 5.5943 0.0000 0.3992 0.8299
CMA 0.0773 0.1228 0.6300 0.5287 -0.1633 0.3180
Machn Coefficients
==============================================================================
alpha 0.1885 0.1220 1.5446 0.1224 -0.0507 0.4277
Mkt-RF 1.2679 0.0495 25.623 0.0000 1.1710 1.3649
SMB 0.0486 0.0999 0.4867 0.6265 -0.1471 0.2444
HML -0.2814 0.0851 -3.3076 1.9991 -0.4481 -0.1147
RMW -0.5083 0.1075 -4.7273 2.0000 -0.7190 -0.2976
CMA -0.1064 0.1547 -0.6878 1.5084 -0.4096 0.1968
Cars Coefficients
==============================================================================
alpha -0.1514 0.2778 -0.5450 1.4142 -0.6959 0.3931
Mkt-RF 1.4681 0.1095 13.409 0.0000 1.2535 1.6827
SMB 0.3375 0.1406 2.3996 0.0164 0.0618 0.6131
HML 0.0065 0.1486 0.0436 0.9653 -0.2848 0.2977
RMW 0.6392 0.2035 3.1404 0.0017 0.2403 1.0382
CMA 0.3075 0.2126 1.4464 0.1481 -0.1092 0.7241
Trans Coefficients
==============================================================================
alpha 0.0156 0.1568 0.0996 0.9207 -0.2917 0.3229
Mkt-RF 1.0818 0.0507 21.328 0.0000 0.9823 1.1812
SMB 0.1702 0.0741 2.2970 0.0216 0.0250 0.3154
HML 0.2517 0.0731 3.4426 0.0006 0.1084 0.3950
RMW 0.5416 0.0862 6.2850 0.0000 0.3727 0.7104
CMA 0.0648 0.1105 0.5863 0.5577 -0.1518 0.2814
Utils Coefficients
==============================================================================
alpha 0.2464 0.1988 1.2397 0.2151 -0.1432 0.6360
Mkt-RF 0.5470 0.0666 8.2169 0.0000 0.4165 0.6774
SMB -0.1174 0.0877 -1.3387 1.8193 -0.2894 0.0545
HML 0.0515 0.1140 0.4522 0.6512 -0.1719 0.2749
RMW 0.2226 0.1136 1.9596 0.0500 -4.305e-05 0.4453
CMA 0.4470 0.1726 2.5899 0.0096 0.1087 0.7852
Rtail Coefficients
==============================================================================
alpha -0.0696 0.1377 -0.5051 1.3865 -0.3395 0.2003
Mkt-RF 0.9269 0.0482 19.211 0.0000 0.8323 1.0214
SMB -0.0171 0.0758 -0.2252 1.1781 -0.1656 0.1315
HML -0.1040 0.0907 -1.1474 1.7488 -0.2817 0.0737
RMW 0.4848 0.0890 5.4484 0.0000 0.3104 0.6591
CMA 0.0865 0.1401 0.6176 0.5369 -0.1881 0.3612
Finan Coefficients
==============================================================================
alpha 0.1190 0.1287 0.9250 0.3550 -0.1332 0.3712
Mkt-RF 1.0351 0.0324 31.916 0.0000 0.9715 1.0987
SMB -0.1543 0.0613 -2.5162 1.9881 -0.2745 -0.0341
HML 0.8463 0.0653 12.969 0.0000 0.7184 0.9742
RMW -0.1587 0.0623 -2.5483 1.9892 -0.2808 -0.0366
CMA -0.2234 0.0852 -2.6212 1.9912 -0.3905 -0.0564
Other Coefficients
==============================================================================
alpha -0.0532 0.1280 -0.4160 1.3226 -0.3041 0.1976
Mkt-RF 1.0318 0.0172 59.846 0.0000 0.9980 1.0656
SMB -0.0411 0.0334 -1.2293 1.7810 -0.1065 0.0244
HML -0.1615 0.0273 -5.9097 2.0000 -0.2151 -0.1079
RMW -0.1326 0.0372 -3.5686 1.9996 -0.2055 -0.0598
CMA -0.0951 0.0583 -1.6300 1.8969 -0.2095 0.0193
==============================================================================
Covariance estimator:
HeteroskedasticCovariance
See full_summary for complete results5. 글을 마치며
이번 글에서는 대표적인 선형 팩터 모델인 파마-프렌치 모델에 대해 정리해보았고, 잔차의 계열상관이 존재할 가능성이 높은 패널 데이터 구조를 고려한 파마-맥베스 회귀모델이 무엇인지 살펴보았다. 글을 쓰면서 생긴 의문들이 있어서 기록해두려고 한다.
이 모델을 어떻게 트레이딩에 활용할 수 있을까?
- 파마-프렌치 모델에서 각 팩터들이 자산의 수익률을 얼마나 잘 설명하는지 확인하고, 리스크 팩터를 만들때 사용한 메트릭으로 순위를 매겨 일정 순위 이상의 자산은 매수하고 일정 순위 이하의 자산은 매도하는 형태의 트레이딩을 하는 것 같긴 한데 이게 맞는지는 잘 모르겠다.
- 스터디를 하면서 피드백을 받았는데 위에서 이해한 방식이 맞다고 한다.
파마-맥베스 회귀 모델이 잔차의 계열상관을 어떻게 보정하는 것인지?
- 시간축에 대해 평균을 내는 과정에서 잔차의 계열 상관성이 줄어들게 되는 건가라는 생각이 드는데, 파마-맥베스 회귀가 제안된 1979년 논문에서도 이에 대한 명확한 설명은 찾지 못했다. 패널 데이터 분석에 관해 공부를 좀 더 해봐야 어떤 의미인지 이해할 수 있을 것 같다.
- 위키피디아 설명을 보면 잔차의 계열상관이 아니라 자산군 간의 상관성을 보정하는 것이라고 나와있는데, 어떤 설명이 맞는 것인지 모르겠다.
Note that Fama MacBeth regressions provide standard errors corrected only for cross-sectional correlation. The standard errors from this method do not correct for time-series autocorrelation. This is usually not a problem for stock trading since stocks have weak time-series autocorrelation in daily and weekly holding periods, but autocorrelation is stronger over long horizons.
This means Fama MacBeth regressions may be inappropriate to use in many corporate finance settings where project holding periods tend to be long. For alternative methods of correcting standard errors for time series and cross-sectional correlation in the error term look into double clustering by firm and year.
회귀계수 추정을 2단계에 걸쳐 하는 것이 오히려 정보를 왜곡시키는 결과를 만들어낼 수 있는 것은 아닌지?
- 스터디를 하면서 나온 의견인데, 추정을 두 번 하면서 정보가 너무 뭉게지는 것은 아닌가 하는 것이다. 파마-맥베스 회귀가 1973년에 나온 방법론이고 약간은 나이브한 측면도 있는 것 같아보이는데, 패널 데이터 분석에서 사용하는 fixed-effect model, random-effect model을 사용하는 것이 더 정확하게 계수 추정을 하는 방법이지 않을까 하는 생각이 든다.
6. 파마-프렌치 모델 관련 추가로 볼만한 자료들
(1) 파이썬으로 배우는 포트폴리오 - 6.3 파마-프렌치 3요인 모델
파이썬으로 배우는 포트폴리오: 6.3 파마-프렌치 3요인 모델
thebook.io
(2) 삼성증권 2018 Back to Basic, Fama-French 3 팩터 모델 - 전편
(3) 삼성증권 2018 Back to Basic, Fama-French 3 팩터 모델 - 후편
(4) Fama-MacBeth regression original paper(1979)
- 2013년 노벨 경제학상 수상 [본문으로]
- The Cross-Section of Expected Stock Returns, 1992; Common risk factors in the returns on stocks and bonds, 1993 [본문으로]
- 잔차의 이분산성, 잔차의 계열상관, 다중공선성 등 [본문으로]
- 표준오차의 과소추정으로 인해 t통계량이 과대추정되어 실제로는 유의하지 않은 변수가 유의하다고 나올 수 있음 [본문으로]
- 삼성증권 2018 Back to Basic, Fama-French 3 팩터 모델 - 전편 [본문으로]